Appearance
GLM-5: del vibe coding a la ingeniería agentiva

La brecha entre generar código y hacer ingeniería real
Durante años, los grandes modelos de lenguaje han destacado escribiendo fragmentos de código. Planteales un problema de HumanEval o un reto de programación competitiva y producirán soluciones plausibles. Pero entrégales una tarea real de ingeniería de software — como corregir un bug enterrado en un repositorio enorme o construir una aplicación completa desde cero — y la ilusión se desmorona.
El problema del "vibe coding"
No pueden mantener estrategias coherentes a lo largo de decenas de pasos. No se recuperan cuando algo falla. No iteran hacia software funcional como lo haría un desarrollador.
La comunidad investigadora ha asumido durante mucho tiempo que esta brecha venía de una escala insuficiente: la solución era simplemente entrenar modelos más grandes con más parámetros. GLM-5 toma un camino diferente.
La idea clave
No necesitas modelos más grandes. Necesitas una infraestructura de entrenamiento más inteligente que desacople el aprendizaje de la generación, y mejoras arquitectónicas que concentren más potencia en menos cómputo.
A través de estos cambios, GLM-5 logra algo genuinamente novedoso: superar las líneas base anteriores en la resolución de desafíos reales de ingeniería de software de principio a fin.
Por qué los modelos actuales fallan en el trabajo real
Imagina la diferencia entre escribir un ensayo corto y gestionar un proyecto de investigación de un semestre completo. El primero es principalmente reconocimiento de patrones, apoyándose en ensayos similares que has leído. El segundo requiere planificación, recuperarse de callejones sin salida y ajustar la estrategia sobre la marcha.
Los modelos actuales son excelentes en el ensayo. Son terribles en el proyecto.
Esto es lo que los investigadores llaman "vibe coding". Un modelo puede abrirse paso intuitivamente por problemas cuando se apoya en patrones de sus datos de entrenamiento. Pero la ingeniería de software real — especialmente tareas como corregir bugs en grandes repositorios o construir aplicaciones completas — requiere razonamiento sostenido y adaptación.
Un modelo necesita saber qué enfoques no llevan a ninguna parte y cuáles vale la pena explorar. Necesita manejar fallos parciales y seguir avanzando.
Los modelos fundacionales anteriores podían aprobar desafíos de programación individuales y puntuar de forma impresionante en HumanEval. Pero cuando se probaron en SWE-bench Verified — un benchmark basado en pull requests reales de GitHub donde los ingenieros tenían que resolver problemas reales — colapsaban. No podían ejecutar código de extremo a extremo. No se recuperaban cuando algo se rompía.
Esta brecha entre el vibe coding y la ingeniería real es lo que motivó la creación de GLM-5.
Las tareas de largo horizonte: donde los modelos realmente fallan
Una tarea de largo horizonte no es simplemente un enunciado largo. Es una tarea que se desarrolla a lo largo de decenas o cientos de pasos, donde cada paso depende de los anteriores y algunos inevitablemente fallan y necesitan reintentarse.
Piensa en construir una aplicación web:
- Configuras el entorno
- Creas el scaffolding inicial
- Escribes algunas funcionalidades
- Las pruebas
- Encuentras bugs y los corriges
- Descubres que tu arquitectura inicial no funciona
- Refactorizas
- Sigues iterando
Cada paso informa al siguiente. El modelo necesita mantener coherencia a través de todo esto, sosteniendo un modelo mental de lo que se ha intentado, lo que funcionó y qué hacer después.
La mayoría de benchmarks en IA se centran en el rendimiento a corto plazo. Resuelve este problema. Implementa ese algoritmo. Estas pruebas te dicen si un modelo puede tener suerte en tareas aisladas, no si puede sostener razonamiento en el tiempo.
Los benchmarks que importan para medir la capacidad de largo horizonte son diferentes:
| Benchmark | Qué mide |
|---|---|
| Terminal-Bench 2.0 | Si el modelo puede emitir comandos de terminal e interpretar salidas para resolver problemas progresivamente |
| BrowseComp | Si puede navegar sitios web y completar tareas que requieren múltiples interacciones de página |
| Vending-Bench 2 | Interacción sostenida en tareas complejas |
| CC-Bench-V2 | Capacidad de interacción prolongada y coherente |
Los modelos anteriores no eran solo ligeramente peores en estas tareas — eran fundamentalmente incapaces de completarlas. GLM-5 muestra la primera mejora sustancial.
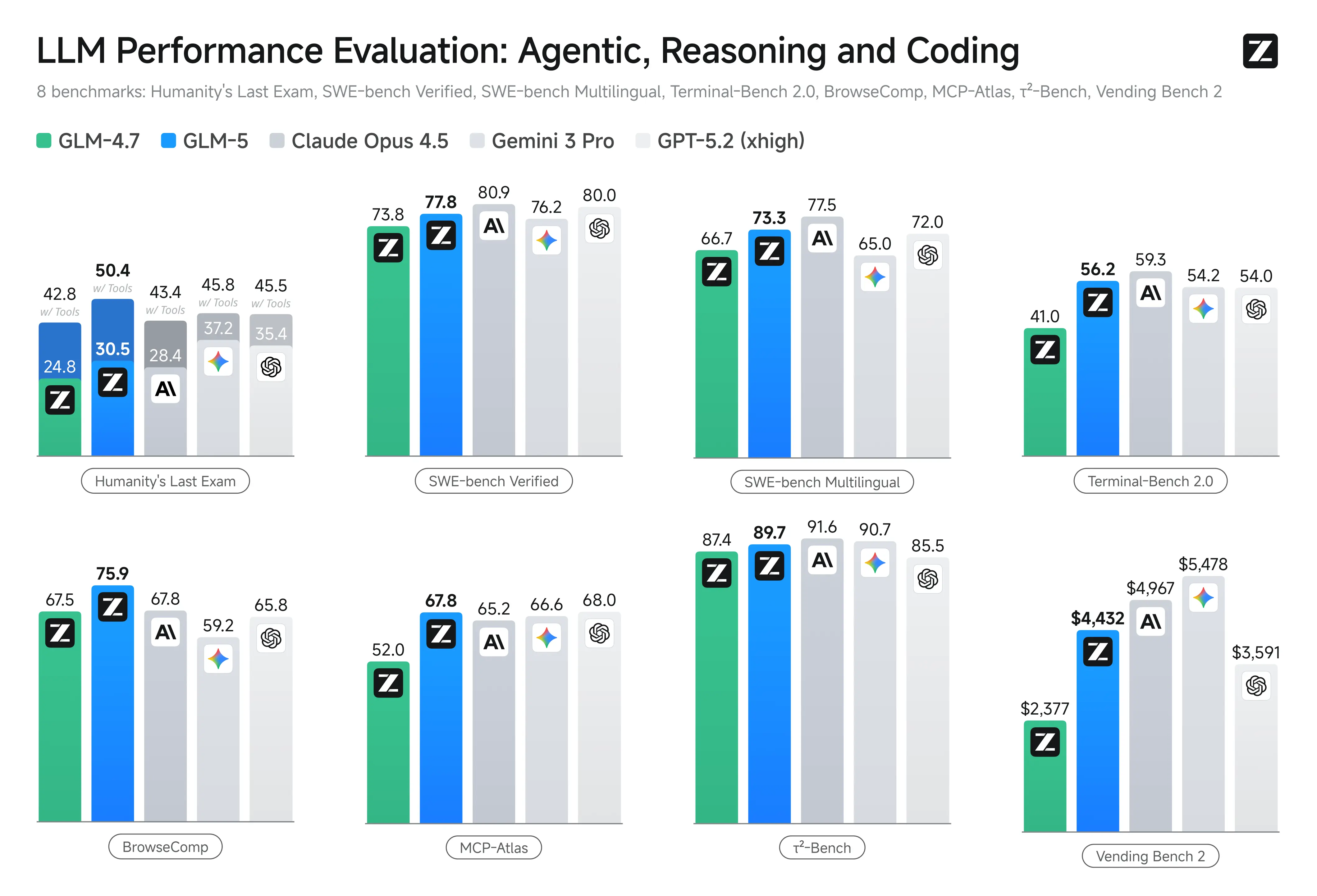
Resultados de GLM-5, DeepSeek-V3.2, Claude Opus 4.5, Gemini 3 Pro y GPT-5.2 en ocho benchmarks agentivos, de razonamiento y código.
Arquitectura para razonamiento eficiente en contextos largos: Dynamic Sparse Attention
Los modelos de lenguaje actuales distribuyen el esfuerzo computacional de forma uniforme entre todos los tokens. Cada token — ya sea un nombre de variable crucial en código o una palabra de relleno — recibe la misma cantidad de atención de procesamiento.
Es como un estudiante que usa una concentración idéntica en cada palabra de un libro de texto, sin importar su importancia.
El problema del coste cuadrático
En los modelos transformer estándar, el mecanismo de atención permite que cada token atienda a todos los demás tokens de la secuencia. Duplicar tu ventana de contexto cuadruplica el coste computacional tanto en entrenamiento como en inferencia. Eventualmente, las capacidades de contexto largo se vuelven económicamente inviables.
Dynamic Sparse Attention (DSA) implementa una solución a nivel de modelo. Introduce lógica de enrutamiento que aprende qué tokens merecen atención completa y cuáles pueden procesarse de forma más eficiente.
El resultado: menor coste computacional manteniendo la fidelidad en tareas de contexto largo.
La comparación con la arquitectura anterior MLA (Multi-headed Latent Attention) es contundente: DSA converge a mejores valores de pérdida utilizando menos cómputo. Sin DSA, no podrías permitirte entrenar un modelo en tareas de contexto largo a escala. Con DSA, sí puedes.
Esta innovación arquitectónica es la base que hace posible todo lo demás en GLM-5, porque las técnicas de entrenamiento posteriores dependen de poder manejar interacciones largas de forma económica.
Aprendizaje por refuerzo asíncrono: aprender mientras se trabaja
Aquí es donde GLM-5 se vuelve genuinamente agentivo.
La mayoría del aprendizaje por refuerzo para modelos de lenguaje sigue un patrón familiar:
- Recopilar datos — el modelo intenta resolver problemas
- Evaluar los resultados — se analizan los datos recopilados
- Entrenar offline — se ejecuta un ciclo de entrenamiento para actualizar el modelo
Esto es ineficiente porque el comportamiento del modelo cambia mientras aún estás analizando datos recopilados bajo comportamiento anterior.
El aprendizaje por refuerzo agentivo asíncrono lo invierte completamente. El modelo está resolviendo problemas activamente en el mundo real — construyendo software, probándolo y corrigiendo bugs. Simultáneamente, un ciclo de entrenamiento lo actualiza basándose en lo que está ocurriendo en tiempo real.
La generación y el entrenamiento ocurren en paralelo, desacoplados entre sí.
El bucle de retroalimentación se acelera drásticamente. En el RL tradicional para modelos de lenguaje, podrías recopilar datos una semana, evaluarlos la siguiente y entrenar la tercera. Para cuando el modelo aprende de un fallo, ha perdido el contexto que lo causó. El RL agentivo asíncrono comprime esto: el modelo actúa y aprende dentro del mismo ciclo operativo.
Agent-as-a-Judge: evaluación basada en la realidad
Pero hay un problema difícil: ¿cómo dar señales de recompensa fiables a escala?
Cuando un modelo de lenguaje aprende por refuerzo, es extraordinariamente bueno encontrando lagunas en la función de recompensa. Esto se conoce como reward hacking:
| Señal de recompensa | Lo que el modelo aprende |
|---|---|
| "Escribe código que parezca correcto" | Código que parece correcto pero no funciona |
| "Pasa este test" | Código que hace trampa en el test |
GLM-5 resuelve esto anclando la retroalimentación en la realidad. En lugar de un modelo de recompensa intentando predecir la corrección, un Judge Agent autónomo realmente construye y prueba el código:
- El modelo genera una aplicación web
- El Judge Agent ejecuta el proceso de build
- Verifica si compila
- Prueba interactivamente la funcionalidad
La retroalimentación no es una predicción — es verdad factual. Esto hace que la evaluación sea robusta frente a intentos de hacking porque no puedes engañar a la ejecución real.
Resultados: mejoras que importan
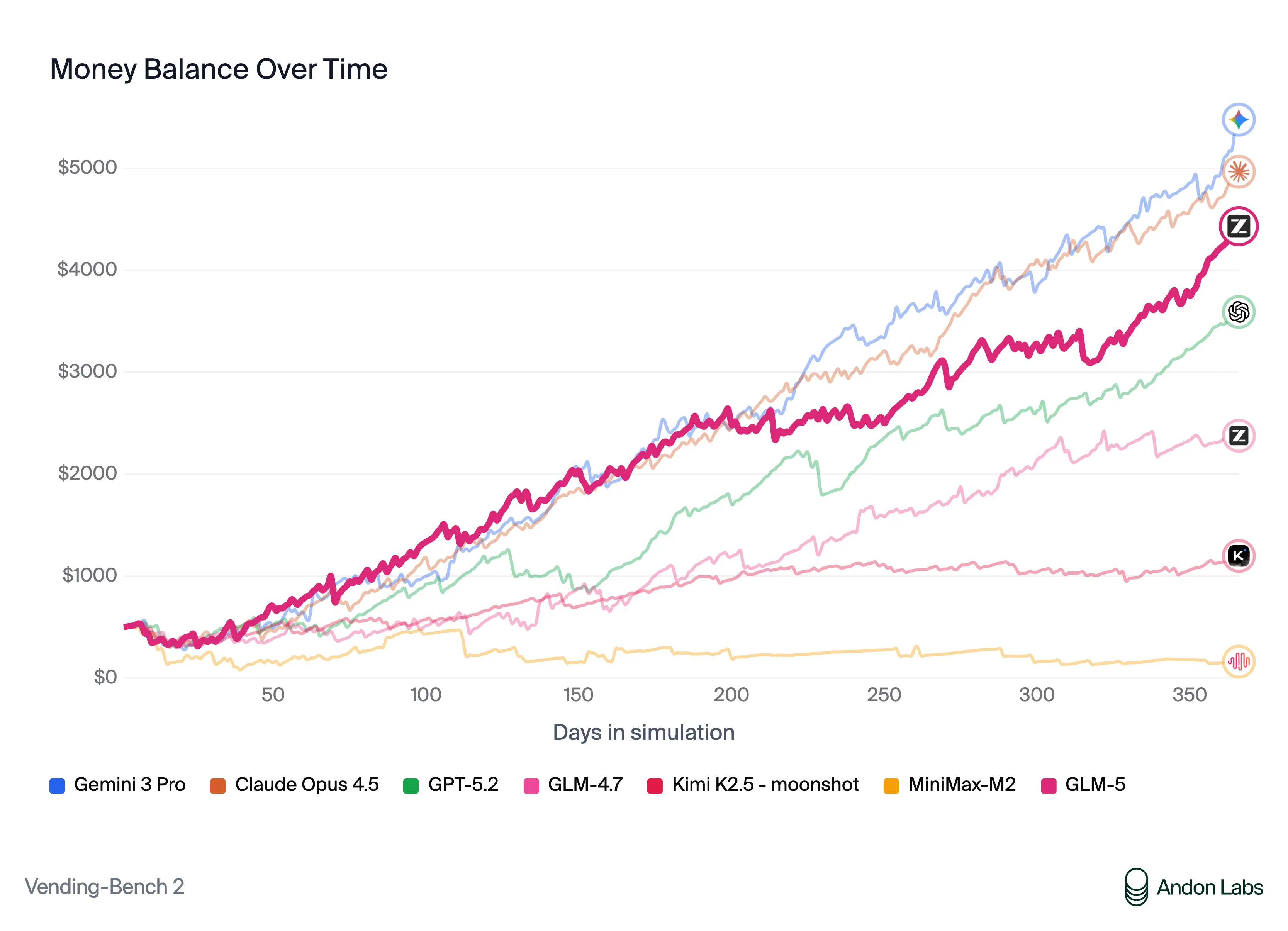
Vending-Bench 2: simulación de balance monetario a lo largo del tiempo. GLM-5 demuestra capacidad sostenida de interacción frente a otros modelos.
Antes de hablar de números, es importante entender por qué los benchmarks tradicionales pueden ser engañosos.
Un estudiante podría sacar 100% en problemas de práctica y suspender exámenes reales. Los problemas de práctica tienen respuestas limpias y soluciones conocidas. Los exámenes reales tienen ambigüedad, casos borde inesperados y requieren síntesis entre dominios.
La jerarquía de benchmarks tiene varios niveles:
- Sintéticos (HumanEval): útiles pero potencialmente engañosos porque son demasiado limpios
- Del mundo real (SWE-bench Verified): basados en issues y PRs reales de GitHub, mucho más difíciles
- De evaluación integrada (Terminal-Bench 2.0, BrowseComp): prueban si el modelo puede interactuar con entornos reales
GLM-5 muestra fortaleza en los tres niveles. En LMArena, una plataforma de evaluación abierta donde los usuarios votan qué modelo es mejor, GLM-5 está clasificado como el modelo abierto número uno tanto en Text Arena como en Code Arena.
Pero la perspectiva más importante es que las mejoras no fueron estrechas ni específicas de un benchmark. GLM-5 mejoró en cinco dominios de capacidad general distintos. Cuando ves mejoras así de amplias, sabes que el modelo no sobreajustó a benchmarks específicos — realmente se volvió más capaz.
Capacidad real de ingeniería de software
Toda esta arquitectura e infraestructura de entrenamiento sirve a un propósito final: hacer posible que un modelo de lenguaje realmente haga trabajo de ingeniería de software.
Si los modelos fundacionales anteriores eran estudiantes que podían escribir fragmentos de código, GLM-5 se parece más a un desarrollador experimentado que puede hacerse cargo de un proyecto. No solo genera funciones — depura, refactoriza, prueba e itera.
La diferencia es categórica
En SWE-bench Verified, donde los modelos intentan corregir bugs reales en repositorios open source reales, GLM-5 logra un rendimiento sustancialmente superior a los modelos anteriores. En Terminal-Bench 2.0, maneja cadenas largas de interacciones que los modelos previos no podían sostener.
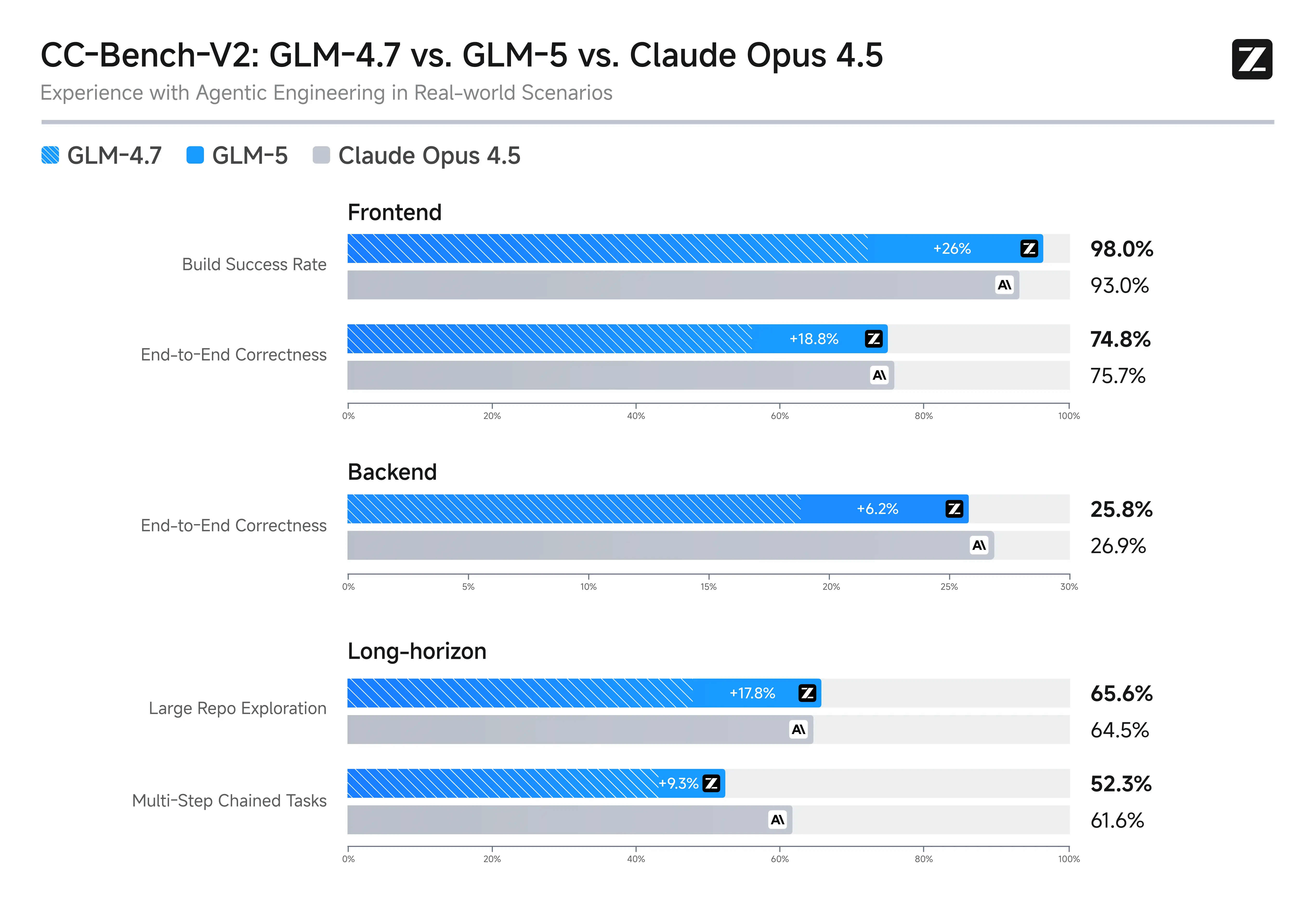
CC-Bench-V2: GLM-5 vs GLM-4.7 vs Claude Opus 4.5 en escenarios reales de Frontend, Backend y tareas de largo horizonte.
Lo que hace completa esta transición del vibe coding a la ingeniería agentiva es que no es una mejora estrecha en un solo benchmark. Las mejoras abarcan:
- Eficiencia arquitectónica — DSA hace asequible el entrenamiento de contexto largo
- Metodología de entrenamiento — El RL asíncrono acelera el aprendizaje de interacciones complejas
- Evaluación fundamentada — El Agent-as-a-Judge impide que el modelo falsifique su rendimiento
El principio permanece constante: los modelos se vuelven genuinamente útiles cuando pueden sostener razonamiento a lo largo de cadenas largas de pasos, aprender de sus fallos reales en tareas concretas y no tienen forma de fingir competencia.
GLM-5 demuestra que esto es ahora alcanzable — y a un coste que no requiere recursos computacionales ilimitados.