Appearance
El mito del contexto infinito: por qué el problema no son solo los tokens

HYPE
Actualmente existe mucho hype alrededor de estas herramientas como claude code, codex y opencode, openclaw, etc... De como el vibeCoding y la igeniera de software está en peligro, pero la realidad es que las IA tienen un límite, son procesadores de texto, no piensan ni razonan como humanos, y su capacidad de mantener coherencia global es limitada.
En el debate sobre los LLM y el contexto siempre aparece la misma afirmación:
"A partir de X tokens empiezan a fallar."
"Aumentar la ventana es carísimo."
"Siempre habrá un límite."
Y es cierto. Pero el problema real no es simplemente el tamaño del contexto. Es más profundo.
Atención no es memoria
Un LLM no "recuerda". Opera dentro de una ventana de contexto activa.
En un Transformer clásico:
| Propiedad | Implicación |
|---|---|
| N tokens en contexto | La atención computa una matriz N x N |
| Complejidad | O(n²) temporal y espacial |
| Más tokens | Más coste, más interferencias, más ruido |
El modelo no tiene memoria infinita. Tiene una RAM cognitiva temporal.
Además, la atención no se distribuye de forma uniforme. El paper "Lost in the Middle" (Stanford/Berkeley, 2023) demostró que los LLMs prestan mucha más atención al inicio y al final del contexto, mientras que la información situada en el medio tiende a ignorarse:
Precisión (%)
100 │ ██ ██
90 │ ████ ████
80 │ ██████ ██████
70 │ ████████ ████████
60 │ ██████████ ██████████
50 │ ████████████ ████████████
40 │ ██████████████ ██████████████
30 │ ████████████████ ████████████████
20 │ ██████████████████████████████████
└──────────────────────────────────────
Inicio Medio Final
Posición en el contextoLa curva en forma de U muestra que la precisión cae drásticamente cuando la información relevante se coloca en el medio del contexto, con caídas de hasta un 30% respecto al inicio o final.
Esto significa que no basta con meter información relevante en el contexto. Dónde la colocas importa tanto como qué colocas.
La memoria total del sistema (vector DB, base de datos, repositorio completo) puede ser enorme. Pero la memoria activa simultánea siempre es limitada. Y ese límite no desaparece.
El falso dilema: más tokens vs mejor filtrado
Una postura dice:
"La solución es aumentar la ventana."
Otra responde:
"La solución es filtrar mejor."
Ambas son incompletas.
Si metes todo en el prompt, colapsa. Si filtras mal, también colapsa. Pero incluso filtrando perfecto, llegará un punto donde el subconjunto realmente necesario será demasiado grande para caber en la ventana.
Ese es un límite estructural.
Cuando el filtrado también falla
En sistemas grandes, por ejemplo proyectos de código complejos, ocurre esto:
- El LLM duplica patrones
- Arregla algo y rompe otra parte
- Introduce abstracciones inconsistentes
- Mezcla estilos arquitectónicos
¿Por qué? Porque no tiene un modelo global coherente persistente. Solo ve snapshots parciales.
Aunque el retrieval sea bueno, el modelo no mantiene:
- Invariantes arquitectónicas fuertes
- Contratos globales persistentes
- Un grafo completo activo de dependencias
Opera localmente. Y los errores globales aparecen.
"Pero un humano sí sabe qué es relevante"
Aquí surge otra afirmación común. En realidad, el humano también es probabilístico.
El cerebro funciona mediante predicción bayesiana, heurísticas, activación asociativa y compresión conceptual extrema. La diferencia no es que el humano no tenga límite. La diferencia es que:
| Humano | LLM |
|---|---|
| Maneja jerarquías de abstracción | Maneja tokens en secuencia |
| Comprime brutalmente información | Opera sobre datos extendidos |
| Reformula el problema dinámicamente | Sigue el flujo del contexto |
| Externaliza estado (notas, herramientas) | Depende de lo que está en la ventana |
La memoria de trabajo humana es pequeña (~4-7 elementos). Pero cada elemento es una abstracción comprimida enorme.
El LLM maneja más tokens. El humano maneja mejores compresiones.
El verdadero límite
Hay dos tipos de límite:
1. Límite de ventana (atención / tokens)
2. Límite de complejidad del problema
El segundo es más profundo.
Si el problema requiere mantener simultáneamente demasiadas variables activas, ningún sistema, humano o artificial, puede sostenerlo todo a la vez.
En ese punto:
- El filtrado cuesta casi lo mismo que procesarlo todo
- La atención se satura
- La coherencia global se degrada
No es un fallo del modelo. Es una propiedad matemática de sistemas complejos.
La perspectiva técnica: entropía y complejidad
Podemos verlo en términos informacionales.
Si el problema tiene entropía H(P) y la ventana activa tiene capacidad informacional C, entonces:
Si H(P) > C
→ El sistema necesita compresión
Si la compresión no es posible sin pérdida crítica
→ Aparece degradación estructuralEn proyectos de código grandes esto se manifiesta como:
- Abstracciones inconsistentes
- Duplicación de lógica
- Violación de invariantes globales
- Refactors que rompen coherencia arquitectónica
No es ruido estocástico puro. Es pérdida de coherencia global por insuficiencia de estado activo.
Degradación de rendimiento vs tokens
A medida que aumenta el número de tokens en el contexto, el rendimiento no se mantiene estable. El benchmark NoLiMa lo demuestra con datos reales de los principales modelos:
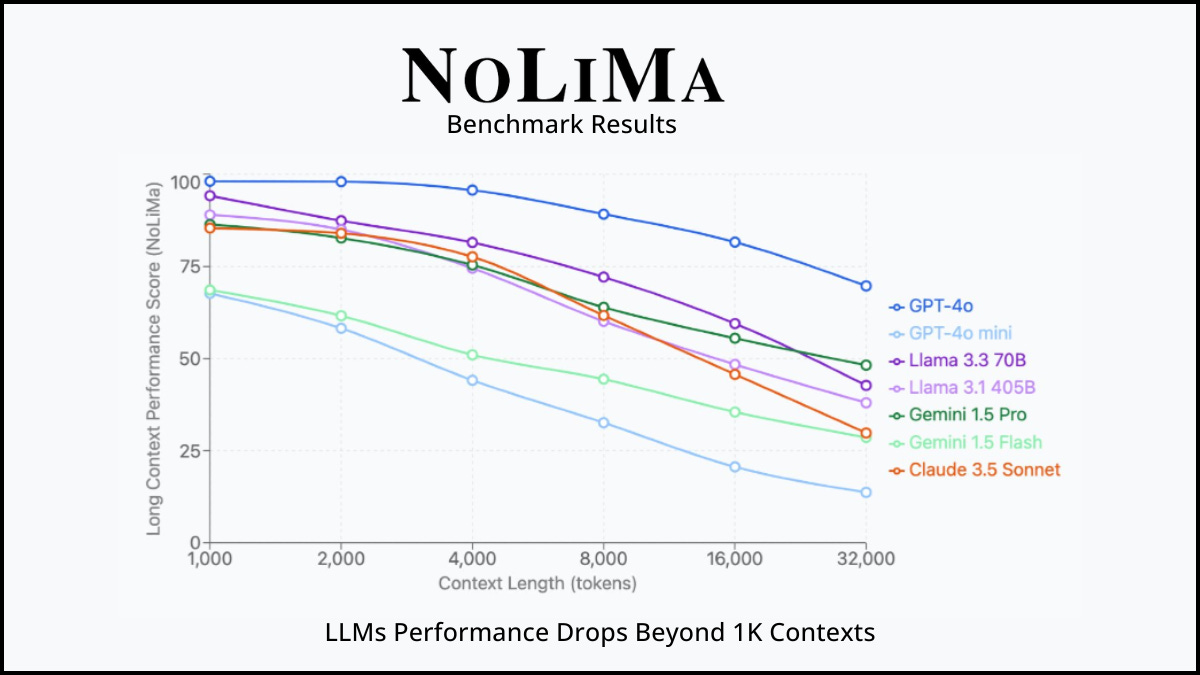
Todos los modelos, incluidos GPT-4o, Claude, Gemini y Llama, muestran una caída clara a partir de los 1.000-4.000 tokens. La relación es predecible:
Rendimiento
100% │ ████████
90% │ ██████████████
80% │ ██████████████████
70% │ ██████████████████████
60% │ ██████████████████████████
50% │ ██████████████████████████████
40% │ ██████████████████████████████████
30% │ ██████████████████████████████████████
└──────────────────────────────────────────
4k 16k 32k 64k 128k 256k
Tokens en contexto| Rango de tokens | Comportamiento típico |
|---|---|
| 0 - 8k | Rendimiento óptimo, alta coherencia |
| 8k - 32k | Degradación leve, empiezan las inconsistencias |
| 32k - 64k | Degradación notable, duplicaciones frecuentes |
| 64k - 128k | Pérdida significativa de coherencia global |
| 128k+ | El modelo opera por "snapshots", pierde el hilo |
Más tokens no es igual a más inteligencia. A partir de cierto umbral, cada token adicional diluye la señal en lugar de reforzarla.
El coste cuadrático: por qué O(n²) importa
El mecanismo de atención de un Transformer compara cada token con todos los demás. Esto significa que el coste no crece de forma lineal, sino cuadrática:
| Tokens | Operaciones de atención | Factor |
|---|---|---|
| 1.000 | 1.000.000 | 1x |
| 4.000 | 16.000.000 | 16x |
| 16.000 | 256.000.000 | 256x |
| 64.000 | 4.096.000.000 | 4.096x |
| 128.000 | 16.384.000.000 | 16.384x |
Duplicar el contexto no duplica el coste. Lo cuadriplica.
Esta explosión combinatoria no solo afecta al rendimiento computacional. Afecta a la calidad: más comparaciones implican más posibilidades de interferencia entre señales, dilución de la atención relevante y ruido estadístico.
Dump masivo vs Contexto curado
La diferencia entre volcar todo al contexto y curar lo que entra es dramática:
DUMP MASIVO CONTEXTO CURADO
────────────────── ──────────────────
50 documentos 5 documentos
├── 48k tokens ├── 4k tokens
├── 80% irrelevante ├── 95% relevante
├── O(n²) = 2.304M ops ├── O(n²) = 16M ops
├── "Lost in the Middle" ├── Info al inicio y final
└── Respuesta genérica └── Respuesta precisa
Coste: $$$ Coste: $
Latencia: alta Latencia: baja
Precisión: ~40% Precisión: ~90%El problema no es solo que el dump masivo sea más caro. Es que activamente empeora la respuesta:
- El modelo no puede distinguir señal de ruido en 48k tokens
- La información relevante queda enterrada en el medio (Lost in the Middle)
- La atención se diluye entre miles de relaciones irrelevantes
- El resultado es una respuesta genérica y superficial
El contexto curado invierte esta dinámica: menos tokens, pero cada token cuenta.
El punto crítico del filtrado
Hay un momento donde el espacio de posibles dependencias crece tanto que decidir qué es relevante se aproxima en coste a procesarlo todo. Ahí aparece:
- Explosión combinatoria: las relaciones entre fragmentos crecen factorialmente
- Acoplamiento global fuerte: todo depende de todo, no hay módulos independientes
- Espacios no factorizables: no se puede dividir el problema en subproblemas
En ese régimen, ni más tokens ni mejor retrieval solucionan el problema fundamental.
Cómo los modelos actuales intentan mitigarlo
Los laboratorios de IA no ignoran estos problemas. Estas son las principales técnicas que se están usando en 2025-2026 para optimizar el manejo del contexto:
Optimización de la atención
| Técnica | Qué hace | Usado por |
|---|---|---|
| FlashAttention v3 | Reorganiza los cálculos de atención en bloques para reducir accesos a memoria, sin aproximaciones | GPT-4, Claude, Llama 3 |
| GQA (Grouped-Query Attention) | Comparte claves y valores entre grupos de cabezas de atención, reduciendo memoria | Llama 3, Mistral |
| MLA (Multi-Head Latent Attention) | Comprime K y V en un espacio latente antes de almacenarlos en caché | DeepSeek-V3 |
| Sliding Window Attention | Cada token solo atiende a una ventana local, no a todo el contexto | Mistral, Gemma |
Optimización de la KV Cache
La KV Cache almacena las claves y valores de tokens ya procesados para no recalcularlos. Es lo que permite generar texto rápido, pero crece linealmente con el contexto:
Contexto de 128k tokens con modelo de 70B parámetros
→ KV Cache ≈ 40-80 GB de memoria GPUTécnicas actuales para reducirla:
- PagedAttention (vLLM): gestiona la caché como páginas de memoria virtual, reduciendo el desperdicio a menos del 4%
- KV Cache Quantization: reduce la precisión de los valores almacenados (FP16 → INT8/INT4)
- KV Cache Eviction: elimina tokens poco importantes de la caché dinámicamente
- RocketKV (2025): combina evicción permanente con selección dinámica dispersa, reduciendo memoria con pérdida mínima de precisión
Paralelismo de secuencia
Para contextos muy largos (>128k tokens), se distribuye el procesamiento entre múltiples GPUs:
- Ring Attention: cada GPU procesa un fragmento del contexto y pasa resultados en anillo
- DeepSpeed Ulysses (Microsoft): particiona las cabezas de atención entre GPUs
- Sequence Parallelism: divide la secuencia en chunks que se procesan en paralelo
La realidad
Estas optimizaciones son ingeniería brillante. Permiten manejar contextos más grandes, más rápido y más barato. Pero no resuelven el problema fundamental: la calidad de la atención sigue degradándose con más tokens, Lost in the Middle sigue ocurriendo, y la coherencia global sigue siendo limitada.
Las optimizaciones de hardware e infraestructura mitigan los síntomas. Solo el Context Engineering aborda la causa raíz: qué información entra en la ventana y cómo se estructura.
¿Qué significa evolucionar?
La evolución no es más tokens, más contexto bruto ni más memoria sin estructura.
La evolución es:
| Estrategia | Ejemplo |
|---|---|
| Externalizar estado | Bases de datos, memoria persistente |
| Introducir jerarquía | Descomposición en subsistemas |
| Descomponer problemas | Agentes especializados por tarea |
| Reducir dimensionalidad | Resúmenes estructurados, no volcados |
| Mantener invariantes | Contratos explícitos entre componentes |
| Verificación estructural | AST, grafos de dependencias, tests |
Es decir: arquitectura alrededor del LLM. Esta disciplina tiene nombre propio: Context Engineering, el diseño intencional de todo el entorno de información que rodea al modelo.
La evolución no consiste en eliminar el límite. Consiste en rediseñar la representación del problema para que sea comprimible.
La conclusión incómoda
Siempre habrá un límite. Da igual que filtres perfecto. Da igual que aumentes contexto. Da igual que mejores embeddings.
Si el espacio de estado activo supera la capacidad operativa del sistema, habrá degradación.
La cuestión no es eliminar el límite. Es diseñar sistemas donde ese límite no sea el cuello de botella diario.
El cuello de botella no es solo el tamaño de la ventana. Es la relación entre complejidad estructural y capacidad de compresión. Ahí es donde está el verdadero desafío.
Y eso no es un problema solo de IA. Es un problema fundamental de complejidad.