Appearance
OpenClaw: el cambio trillonario en IA que lo cambia todo para los LLMs locales

La era de la dependencia cloud está terminando
Durante los últimos tres años, los desarrolladores han vivido atados a límites de tasa de API, costes de suscripción desorbitados y la amenaza constante de la recolección de datos por parte de modelos cerrados. Big Tech nos dijo que la IA local era un sueño imposible, que ejecutar modelos frontera requería granjas de servidores del tamaño de ciudades.
Entonces llegó la langosta.
OpenClaw (anteriormente conocido como Clawdbot y luego Moltbot) no solo ha roto el paradigma: lo ha pulverizado en un millón de piezas open-source. Estamos ante el giro más agresivo en infraestructura de IA desde la invención de la arquitectura Transformer.
La ecuación revolucionaria
OpenClaw + MiniMax Agent + Mac M3 = Un centro de comando de agentes completamente local, sin conexión a internet, sin costes recurrentes.
Lo que se consigue:
- Kimi K2.5 local (modelo multimodal MoE de 1 billón de parámetros de Moonshot AI)
- GLM-5 local (modelo MoE de 744B parámetros de Zhipu AI, licencia MIT)
- MiniMax M2.5 local (modelo multimodal MoE con capacidades agentivas avanzadas)
- Un centro de comando de agentes autónomos completo
Esto no es chatear con un LLM offline. Es desplegar una flota de agentes autónomos que escriben código, analizan datasets masivos y orquestan flujos de trabajo complejos, sin contactar jamás un servidor externo.
Cómo OpenClaw disrumpe el futuro de la computación
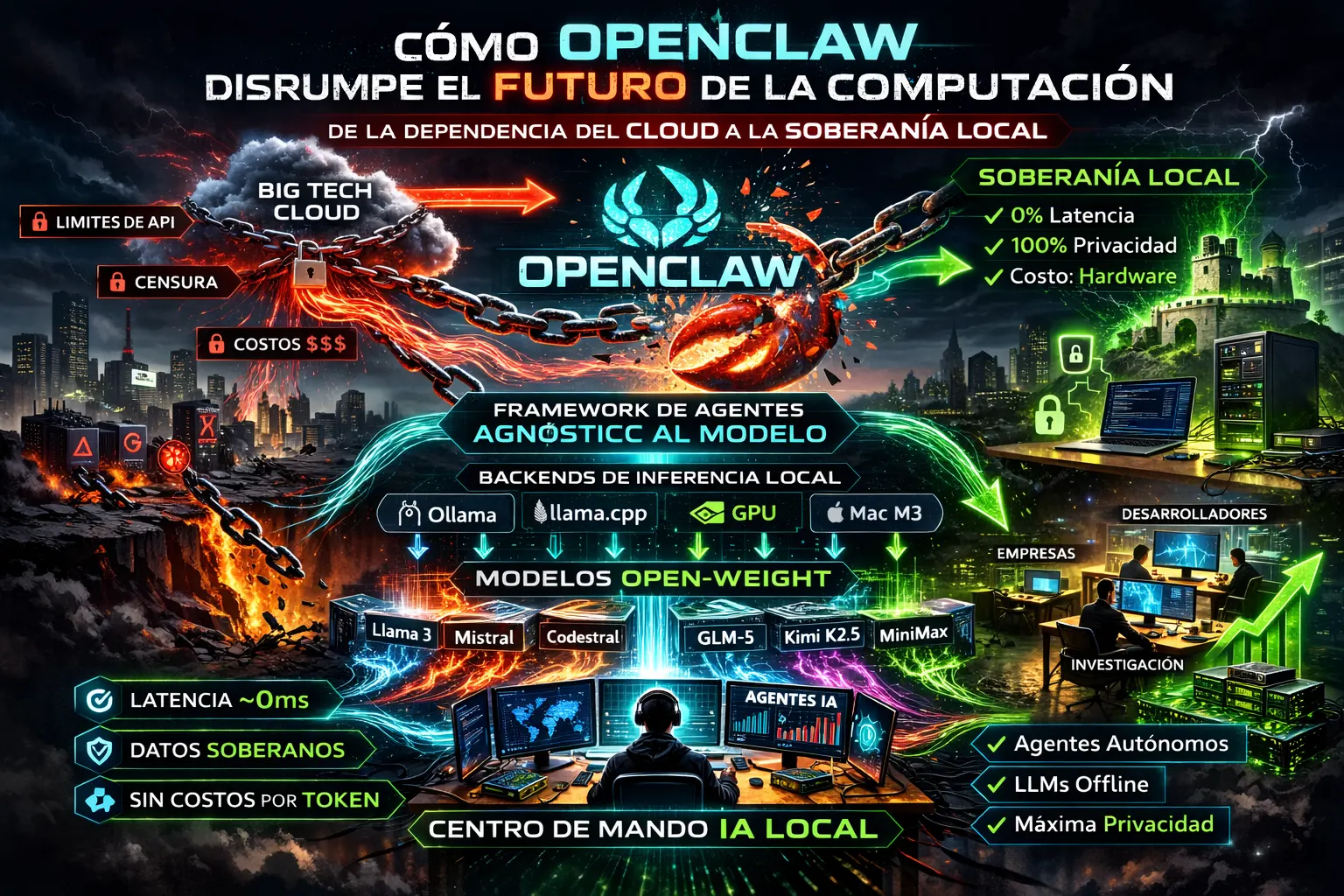
El cuello de botella hasta ahora ha sido claro: la revolución IA era el juego de los gigantes del cloud. Pagas por acceso, juegas con sus reglas, y tus datos son su combustible. OpenClaw altera fundamentalmente esta dinámica de poder actuando como un framework de agentes agnóstico al modelo que conecta modelos open-weight con hardware de consumo a través de backends de inferencia local como Ollama y llama.cpp.
Las cuatro ventajas clave
| Ventaja | Descripción |
|---|---|
| Inferencia con latencia casi cero | Sin round-trip de red. Todo pasa por Ollama localmente, generando tokens de forma casi instantánea |
| Soberanía total de datos | Tu código propietario, documentos y datos corporativos nunca salen de tu disco duro |
| Orquestación sin restricciones | Los modelos open-weight permiten configurar parámetros propios, sin las barreras de las APIs cloud |
| Eliminación de costes por token | Generes diez tokens o diez millones, el coste es el mismo: la electricidad de tu máquina |
La magia reside en la arquitectura agnóstica de OpenClaw combinada con el soporte de cuantización de Ollama. Enruta tareas de agentes a través del LLM local usando formatos cuantizados (GGUF, AWQ, GPTQ) para exprimir cada gota de cómputo de tu memoria unificada.
Stack empresarial tradicional vs. Stack OpenClaw
| Stack cloud tradicional | Stack OpenClaw |
|---|---|
| Base de datos vectorial cloud (de pago) | Chroma / FAISS local |
| API de embeddings (de pago) | Embeddings locales |
| API de inferencia (de pago) | Inferencia local vía OpenClaw + Ollama |
| Rezar para que tus datos no se usen para entrenar | Zero fuga de datos, zero costes recurrentes |
OpenClaw almacena conversaciones, memoria a largo plazo y skills como archivos Markdown y YAML en disco local, permitiendo retención de contexto persistente e inspeccionable. Las startups ya no necesitan millones solo para cubrir sus facturas de OpenAI o Anthropic.
Cómo OpenClaw potencia los agentes autónomos
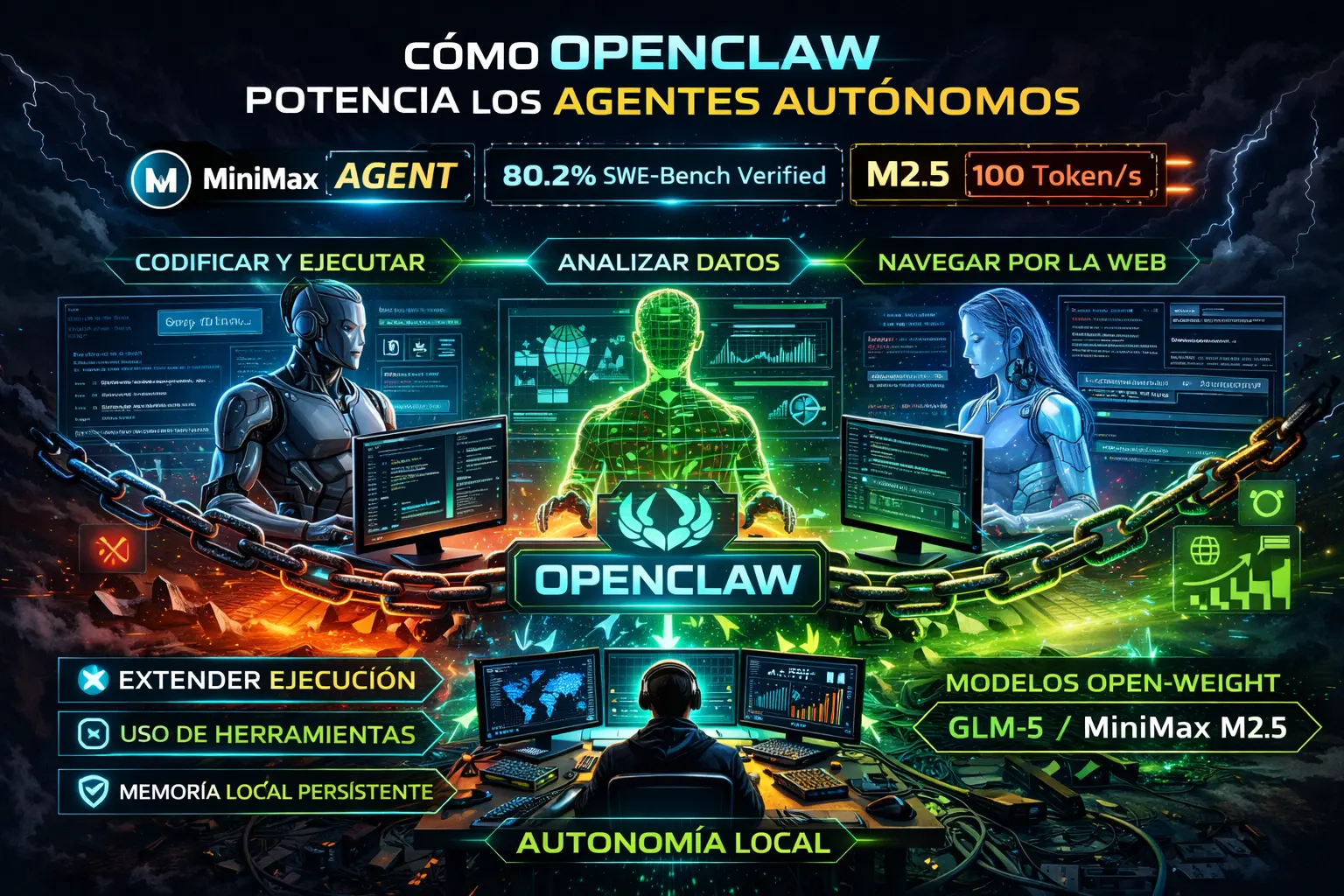
MiniMax Agent — impulsado por el modelo M2.5 — se ha consolidado como un framework de primer nivel para ejecución autónoma de tareas, con un 80.2% en SWE-Bench Verified y 100 tokens/segundo en su variante Lightning. Pero tenía una dependencia: estaba diseñado como servicio cloud. Si la API caía, tu agente moría.
OpenClaw proporciona el trasplante definitivo de sistema nervioso. Al combinar su orquestación local con modelos open-weight ejecutándose en Ollama, se crea una entidad offline imparable.
Capacidades ampliadas
- Ejecución extendida: Sin costes de API, un agente puede ejecutarse durante días de forma recursiva sin arruinarte
- Uso de herramientas hiper-local: Interfaz directa con el sistema operativo — comandos shell, gestión de archivos, compilación de código nativo
- Sinergia multi-modelo: Enrutar monólogos internos a un modelo rápido (Kimi K2.5 cuantizado) y salidas complejas a GLM-5 para razonamiento pesado
- Memoria local persistente: Sistema basado en archivos Markdown en disco que permite recuperar sesiones pasadas sin re-embeddings
Ejemplo de flujo completamente offline
- Depositas un PDF de 500 páginas con datos financieros en una carpeta local
- El agente OpenClaw detecta el archivo mediante vigilancia del sistema de archivos
- Ollama ejecuta un modelo de embeddings local para parsear el documento
- El agente consulta GLM-5 local para extraer métricas clave
- El agente escribe un script Python, lo ejecuta y genera un informe
Sin Wi-Fi. Sin suscripciones.
Configuración segura paso a paso
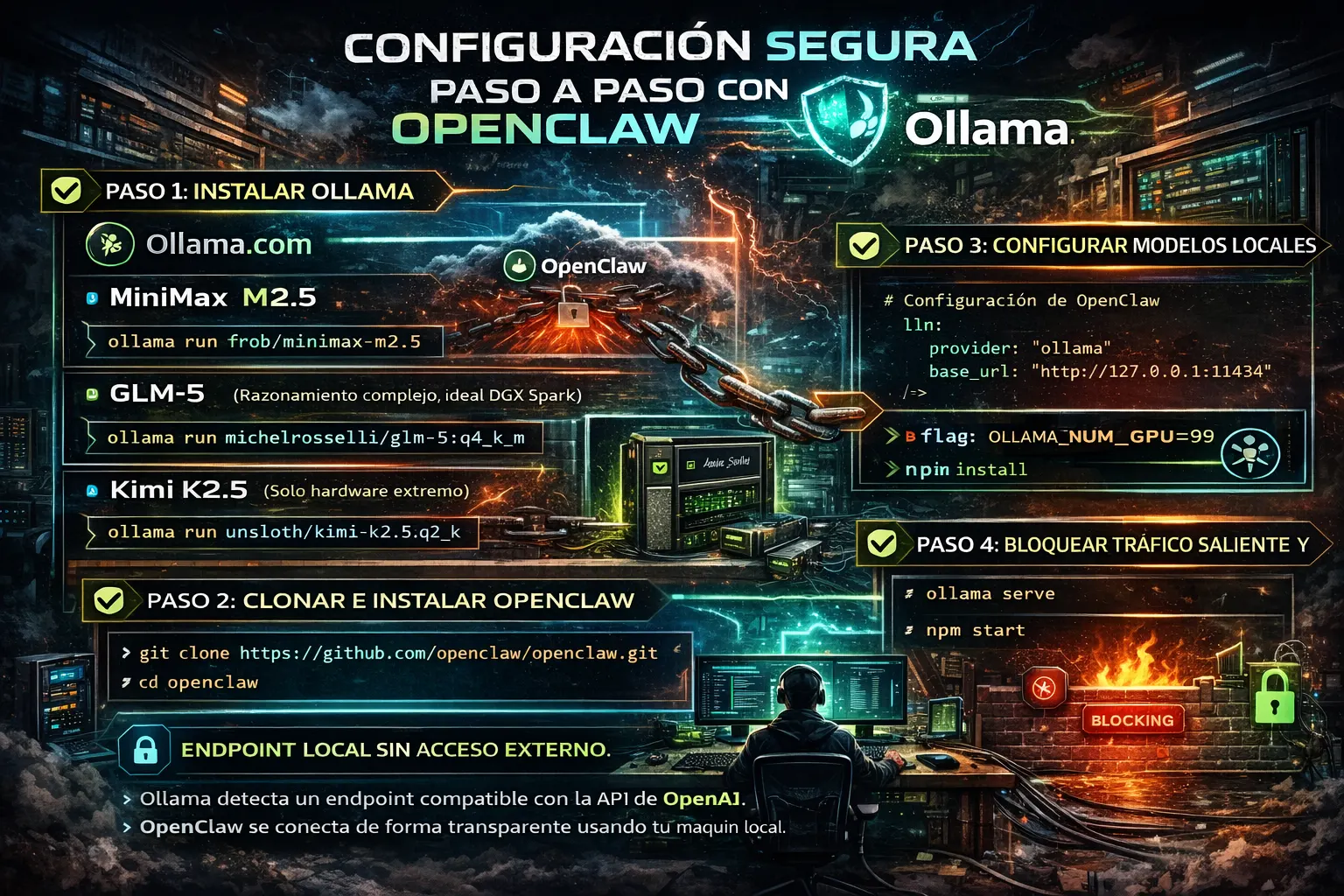
Paso 1: Instalar Ollama
Descarga desde ollama.com. Luego elige tu modelo según tu hardware:
MiniMax M2.5 (recomendado para la mayoría de tareas):
bash
ollama run frob/minimax-m2.5GLM-5 (para tareas complejas de razonamiento, ideal para DGX Spark):
bash
ollama run michelrosselli/glm-5:q4_k_mKimi K2.5 (requiere 240GB+ de VRAM/memoria unificada, solo para hardware extremo):
bash
ollama run unsloth/kimi-k2.5:q2_kOptimización por hardware
| Sistema | Recomendación | Flag |
|---|---|---|
| DGX Spark | Aceleración CUDA. Quants q4_k_m | OLLAMA_NUM_GPU=99 |
| Mac M3 | Memoria unificada. Quants 1-bit/2-bit para modelos grandes | --num-gpu 0 (Metal por defecto) |
Paso 2: Clonar e instalar OpenClaw
bash
git clone https://github.com/openclaw/openclaw.git
cd openclaw
npm installPaso 3: Configurar modelos locales
yaml
# Configuración de OpenClaw
llm:
provider: "ollama"
base_url: "http://127.0.0.1:11434"
# Modelo de planificación (razonamiento complejo)
planner_model: "frob/minimax-m2.5"
# Modelo de ejecución (tareas rápidas y código)
executor_model: "michelrosselli/glm-5:q4_k_m"
# Ajustar según hardware
max_tokens: 8192Paso 4: Bloquear tráfico saliente y lanzar
Configura tu firewall para denegar conexiones salientes desde localhost:11434, y luego:
bash
ollama serve
npm startOllama expone un endpoint compatible con la API de OpenAI, así que OpenClaw se conecta de forma transparente: el framework no distingue entre una API cloud y tu máquina local.
El hardware que hace posible la revolución

La revolución OpenClaw ocurre ahora gracias a una revolución de hardware simultánea.
Apple Silicon: el cambio de juego
- Memoria Unificada (UMA): Un Mac M3 Max con 128GB puede asignar gran parte al GPU para inferencia. Cargar un GLM-5 cuantizado (40-60GB+) directamente en un portátil era ciencia ficción hace pocos años
- Eficiencia: Ejecuta modelos pesados consumiendo una fracción de la energía de un setup GPU tradicional
NVIDIA DGX Spark: potencia de escritorio sin compromisos
- 1 petaFLOP de rendimiento FP4 con el GB10 Grace Blackwell Superchip
- 128GB de memoria LPDDR5x unificada: modelos de hasta 200B parámetros localmente
- ConnectX-7: dos unidades enlazadas vía 100GbE manejan modelos de hasta 405B parámetros
- Tokens generados más rápido de lo que puedes leer
Privacidad como hardware
Cada consulta al cloud es una pieza de tu huella digital que regalas. Con Mac M3 o DGX Spark + OpenClaw:
- Tu estrategia corporativa permanece interna
- Tu código fuente nunca es parseado por servidores de terceros
- La inversión inicial se amortiza eliminando facturas de API permanentemente
El futuro es local y offline
La narrativa de la dominación inevitable del cloud era una campaña de marketing para mantener a los desarrolladores dependientes. La combinación de OpenClaw, modelos open-weight como MiniMax M2.5 y GLM-5, y hardware como el Mac M3 y el DGX Spark ha descentralizado por completo el poder de la IA generativa.
Lo que hemos construido:
- Un framework que elimina costes y latencia
- Un sistema agentivo que opera con autonomía total y sin monitorización externa
- Un centro de comando que respeta la privacidad absoluta de los datos
Estamos pasando de una era de alquilar inteligencia a una era de poseerla.
La langosta ha mudado su caparazón. Se ha desprendido de la cáscara restrictiva de la dependencia cloud y ha crecido una armadura endurecida de cómputo local. La comunidad open-source ha demostrado que la inteligencia real no necesita estar detrás de un muro de pago.
Referencias y enlaces
- OpenClaw en GitHub - Repositorio oficial del framework
- Ollama - Backend de inferencia local
- llama.cpp - Motor de inferencia para modelos GGUF
- MiniMax M2.5 - Modelo multimodal MoE con capacidades agentivas
- GLM-5 (Zhipu AI) - Modelo MoE de 744B parámetros, licencia MIT
- Kimi K2.5 (Moonshot AI) - Modelo multimodal MoE de 1 billón de parámetros
- NVIDIA DGX Spark - Supercomputador de escritorio con GB10 Grace Blackwell
- ChromaDB - Base de datos vectorial open-source para RAG local
- FAISS (Meta) - Biblioteca de similitud vectorial
- Arquitectura Transformer (paper original) - "Attention Is All You Need"
- SWE-Bench Verified - Benchmark de ingeniería de software real