Appearance
Menos datos, más inteligencia: por qué 2.000 ejemplos pueden superar a 300.000
El mantra que ya no funciona
Durante años hemos repetido la misma fórmula en inteligencia artificial:
Más datos = mejor modelo.
Pero ¿y si eso no fuera del todo cierto?
Un trabajo reciente aceptado en ACL 2025 demuestra algo contraintuitivo: puedes igualar el rendimiento de modelos entrenados con cientos de miles de ejemplos usando apenas unos miles... si eliges los correctos.
La clave no está en el texto que ves. Está en el espacio interno del modelo.
El error clásico: confundir variedad con diversidad real
Cuando generamos datos sintéticos para entrenar un modelo, solemos hacer algo así:
- Cambiar palabras.
- Reformular frases.
- Variar el tono.
- Añadir contexto.
Visualmente parecen distintos. Pero internamente, para el modelo, pueden ser casi idénticos.
Es como estudiar 100 ejercicios de matemáticas que en realidad practican exactamente la misma operación. Mucho volumen. Poco aprendizaje nuevo.
El espejismo del volumen
Hasta ahora medíamos la diversidad de datos con herramientas externas: n-gramas, distancias de embeddings, métricas estadísticas. Pero esas métricas no te dicen si el modelo está aprendiendo algo nuevo. Es como medir cuánto estudias, pero no cuánto entiendes.
Lo que realmente importa: las "features" internas
Los LLM no piensan en palabras como nosotros. Piensan en activaciones internas — patrones neuronales que se encienden cuando detectan ciertos conceptos.
Un texto puede activar simultáneamente:
- Una feature de "instrucción formal".
- Una feature de "razonamiento paso a paso".
- Una feature de "tono médico".
- Una feature de "estructura tipo checklist".
Si mil ejemplos activan exactamente las mismas combinaciones internas, el modelo no está aprendiendo nada nuevo después del primero. Ahí es donde aparece el desperdicio masivo.
Ya lo vimos en Más grande ya no escala: activar solo lo necesario: la tendencia clara en la industria es dejar de escalar ciegamente y empezar a activar solo lo que importa. Este paper lleva esa misma filosofía al terreno de los datos de entrenamiento.
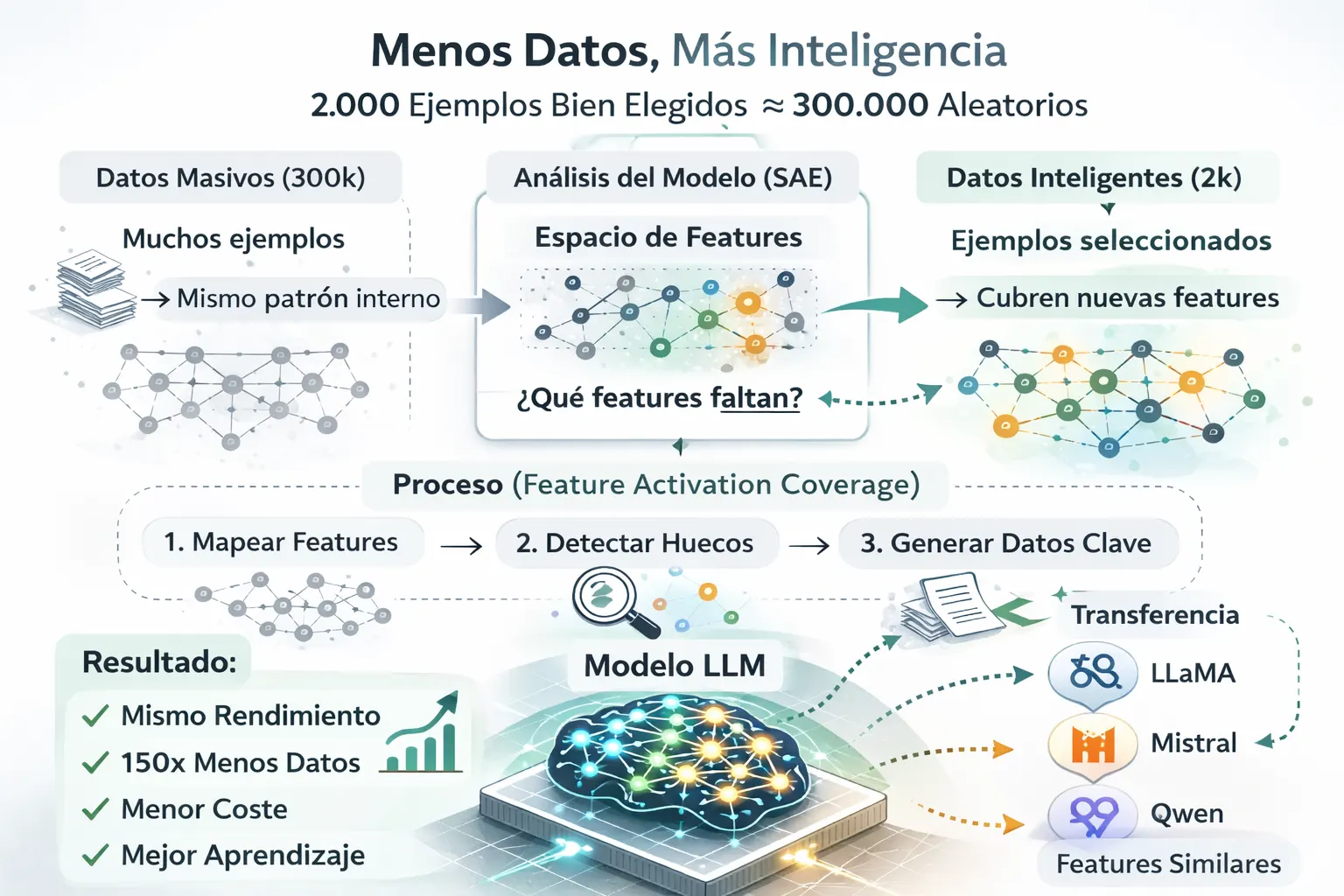
La solución: Sparse Autoencoders para selección de datos
En lugar de preguntarnos:
"¿Estos textos son distintos?"
La pregunta correcta es:
"¿Activan partes distintas del modelo?"
Investigadores de Meta AI y la Universidad de Illinois propusieron exactamente esto en el paper "Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder". El proceso funciona en tres pasos:
1. Mapear el espacio interno del modelo
Se utilizan Sparse Autoencoders (SAEs) — redes neuronales diseñadas para descomponer las activaciones internas de un LLM en features interpretables y monosemánticas. Cada feature captura un concepto específico que el modelo ha aprendido a reconocer.
Los investigadores entrenaron SAEs de tipo TopK sobre Llama-3.1-8B usando 10 mil millones de tokens del dataset RedPajama-V2, obteniendo un mapa detallado de las representaciones internas del modelo.
2. Detectar huecos de cobertura
Se analiza qué features importantes no están siendo activadas por el dataset actual. Cada ejemplo de entrenamiento se pasa por el modelo y se registran las features que activa. Si tu dataset de 300.000 ejemplos solo cubre el 40% de las features relevantes, estás desperdiciando el 60% del potencial de entrenamiento.
3. Generar datos dirigidos con selección inteligente
En lugar de seleccionar ejemplos al azar, los investigadores proponen dos algoritmos:
- SAE-GreedSelect: Selección voraz que acepta un ejemplo solo si activa features que ningún ejemplo previo activó. Maximiza la cobertura de features nuevas en cada paso.
- SAE-SimScale: Acepta ejemplos cuya similitud con los ya seleccionados esté por debajo de un umbral (0.8), diseñado para ser escalable a datasets industriales.
Resultado: cobertura inteligente en vez de volumen bruto.
El descubrimiento inesperado
Los investigadores encontraron una correlación de r = 0.92 entre la longitud del texto y la riqueza de features activadas. Esto explica mecánicamente por qué estrategias anteriores basadas en "seleccionar las respuestas más largas" funcionaban sorprendentemente bien — sin saber por qué, estaban maximizando la cobertura de features.
Los resultados: el volumen pierde contra la precisión
Con este método, los resultados hablan por sí solos:
| Comparación | Resultado |
|---|---|
| 3.000 ejemplos seleccionados con SAE-SimScale | Superan al baseline con dataset completo de 70.000 (WizardLM) en IFEval |
| SAE-GreedSelect | Supera consistentemente a todos los métodos de selección existentes |
| Cobertura de features | Los datos seleccionados activan significativamente más features internas |
Los benchmarks utilizados incluyen:
- IFEval: Evaluación de seguimiento de instrucciones (métricas estrictas y laxas)
- AlpacaEval 2.0: Evaluación por preferencia humana
- MMLU, Winogrande, TruthfulQA, ARC, GSM8k: Tareas de conocimiento y razonamiento
Y lo validaron en múltiples modelos: Llama-2-13b, Llama-2-7b y Gemma-2-9b, confirmando que el método funciona de forma consistente a través de diferentes arquitecturas.
Por qué esto cambia las reglas del juego
Entrenamiento más barato
Menos datos significa menos coste, menos tiempo, menos energía. Si puedes lograr el mismo resultado con 150 veces menos datos, el ahorro en cómputo es brutal.
Más comprensión del modelo
Por primera vez, no solo seleccionas datos — entiendes qué partes internas estás entrenando realmente. Los Sparse Autoencoders abren la caja negra y te muestran exactamente qué features están cubiertas y cuáles no.
Transferibilidad entre modelos
Uno de los hallazgos más fascinantes: los SAEs entrenados sobre un modelo (Llama-3.1-8B) produjeron selecciones de datos que funcionaron igualmente bien en otros modelos como Gemma-2 y Llama-2. Esto sugiere que distintos modelos comparten estructuras internas similares, y que entender las features de uno puede ayudarte a mejorar otro.
Conexión con la interpretabilidad
Este trabajo se apoya en investigación pionera de Anthropic sobre monosemanticit y los SAEs escalables de OpenAI, que demostraron que es posible descomponer modelos masivos en features interpretables. La selección inteligente de datos es una aplicación práctica directa de esa investigación fundamental.
El "pero" necesario
Para implementar esto necesitas:
- Analizar el espacio interno del modelo: Requiere ejecutar los datos a través del modelo y extraer activaciones.
- Entrenar Sparse Autoencoders: No es trivial — los investigadores usaron 10 mil millones de tokens para entrenar los suyos.
- Trabajo previo de interpretación: Identificar qué capas y features son más relevantes (la capa 31 superó consistentemente a la 29 en los experimentos).
No es automático. Pero es mucho más eficiente que el enfoque de fuerza bruta.
Conexión con la ingeniería de contexto
Este descubrimiento no vive aislado. Forma parte de una tendencia mayor en la IA: la era de la eficiencia inteligente.
Ya lo hemos analizado desde múltiples ángulos:
- En Context Engineering vimos cómo diseñar la información que le entregas al modelo importa más que el tamaño de la ventana.
- En El mito del contexto infinito desmontamos la idea de que más tokens resuelven el problema del razonamiento.
- En Modelos Recursivos de Lenguaje (RLM) exploramos cómo el MIT propone descargar el contexto a un entorno externo programable.
La misma filosofía aplica al entrenamiento: no necesitas más datos, necesitas los datos correctos. La inteligencia no escala linealmente con el volumen — escala con la cobertura de lo que el modelo realmente necesita aprender.
Reflexión final
Durante años la carrera fue:
Quién tiene más datos.
Ahora podría convertirse en:
Quién entiende mejor su modelo.
El futuro del entrenamiento no parece ser más grande. Parece ser más inteligente.
Los Sparse Autoencoders nos dan, por primera vez, una lente para mirar dentro de la caja negra y tomar decisiones de entrenamiento basadas en lo que el modelo realmente necesita, no en lo que nosotros creemos que necesita.
Y eso, en un campo donde entrenar un modelo cuesta millones de dólares, no es un detalle menor.
Referencias y enlaces
- Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder (arXiv) — Xianjun Yang, Shaoliang Nie, Lijuan Liu, et al. Aceptado en ACL 2025.
- Towards Monosemanticity: Decomposing Language Models With Dictionary Learning — Anthropic — Investigación fundacional sobre features interpretables en LLMs.
- Scaling and Evaluating Sparse Autoencoders — OpenAI — Paper sobre SAEs a escala industrial.
- Sparse Autoencoders Find Highly Interpretable Features in Language Models (arXiv) — Uno de los papers seminales sobre SAEs para interpretabilidad.
- Más grande ya no escala: activar solo lo necesario — Nuestro análisis sobre la tendencia de activación selectiva en arquitecturas de modelos.
- Context Engineering: La Arquitectura de la IA Confiable — Cómo la calidad del contexto supera a la cantidad.
- El mito del contexto infinito — Por qué más tokens no resuelven el problema del razonamiento.
- Modelos Recursivos de Lenguaje (RLM) — El paradigma del contexto externo programable del MIT.