Appearance
Modelos Recursivos de Lenguaje (RLM): el fin de las alucinaciones por contexto
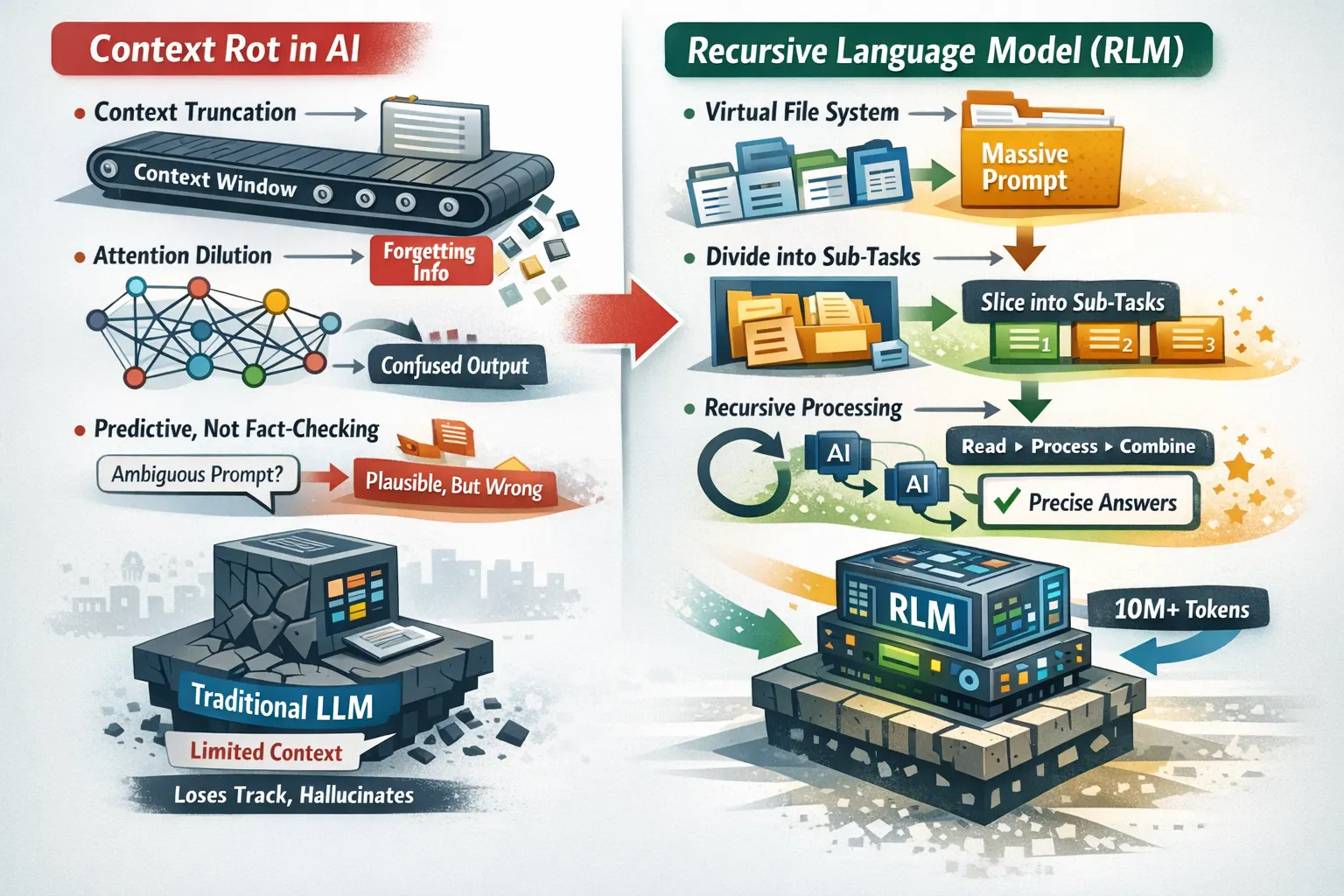
Tu IA pierde el hilo, y no es tu culpa
Si usas IA para tareas de programación profunda o conversaciones prolongadas, probablemente hayas visto cómo la salida se convierte en un sinsentido total. Es la clásica "alucinación de la IA". En sesiones extendidas, estos errores están fuertemente impulsados por los límites de la memoria del modelo, conocida como la ventana de contexto.
Para entender por qué tu asistente de IA eventualmente pierde el hilo, necesitamos examinar tres factores clave.
Los tres enemigos del contexto
1. Truncamiento de la ventana de contexto
Imagina que la ventana de contexto es como una cinta transportadora que solo puede contener 100 palabras. Cuando añades las siguientes 10 palabras, las primeras 10 se caen al vacío. Literalmente se olvidan.
Esto significa que en conversaciones largas, las instrucciones iniciales, el contexto del problema y las decisiones arquitectónicas que estableciste al principio simplemente desaparecen.
2. Dilución de la atención
Incluso con ventanas de tokens enormes, el modelo puede alucinar porque su atención se diluye demasiado. Es como intentar leer un libro entero mientras te piden que recuerdes cada detalle de cada página simultáneamente. El resultado es que el modelo mezcla secciones diferentes de la información en una única respuesta incoherente.
3. La naturaleza de la predicción
Fundamentalmente, los LLM están construidos para detectar patrones, no para verificar hechos. Cuando el prompt es ambiguo, la prioridad del modelo es proporcionar una respuesta plausible que coincida con los patrones aprendidos de miles de millones de líneas de texto. No busca la verdad; busca lo que parece verdadero.
El problema real
Las alucinaciones no son un "bug" que se pueda parchear con un prompt mejor. Son una consecuencia directa de cómo funcionan los Transformers: motores de predicción estadística operando sobre una memoria finita y volátil. Ya hablamos en profundidad sobre esto en El mito del contexto infinito.
La solución de la industria: hacer la ventana más grande
Se han hecho numerosas mejoras para superar lo que se conoce como "Context Rot" (degradación del contexto). Mientras técnicas avanzadas como la condensación de contexto y la compactación de contexto están ganando tracción, la solución más común de la industria ha sido simplemente aumentar el tamaño bruto de la ventana de contexto.
Ejemplos recientes:
| Modelo | Ventana de contexto |
|---|---|
| Google Gemini 3 Pro / Flash | Hasta 1 millón de tokens |
| Anthropic Claude Opus 4.6 | Hasta 1 millón de tokens |
| OpenAI GPT-5.2 | 400.000 tokens |
| Alibaba Qwen3-Coder-480B | 256K nativo, extensible hasta 1M |
Pero como ya analizamos en Context Engineering: La Arquitectura de la IA Confiable, más tokens no significa mejor razonamiento. Es como ampliar un almacén: puedes meter más cosas, pero si no tienes un sistema de organización, encontrar lo que necesitas sigue siendo imposible.
Ingeniería de Contexto: la solución práctica hoy
Mientras la investigación avanza en nuevas arquitecturas, la ingeniería de contexto es la disciplina que hoy te permite maximizar la calidad de las respuestas de tu IA. No se trata solo del tamaño de la ventana, sino de cómo estructuras la información que le entregas al modelo. Boris Tane, Engineering Lead en Cloudflare, describe un flujo de trabajo disciplinado en tres fases —Investigación, Planificación, Implementación— que demuestra cómo la ingeniería de contexto aplicada convierte a Claude Code en una herramienta de producción real, más allá de prototipos o MVPs.
Recursive Language Models: el cambio de paradigma
Aquí es donde la cosa se pone interesante. Investigadores del MIT (Alex L. Zhang, Tim Kraska, Omar Khattab) han propuesto una nueva arquitectura que ataca el problema desde la raíz: los Modelos Recursivos de Lenguaje (RLM).
Los RLM abordan el problema del contexto largo en tiempo de inferencia (es decir, cuando alguien está usando activamente la IA para obtener respuestas). En lugar de forzar un muro masivo de texto dentro de una ventana de contexto restringida, el RLM trata el prompt como un sistema de archivos virtual. Interactúa con la entrada como un entorno externo, dividiendo la carga de trabajo en sub-tareas más pequeñas y manejables, llamándose a sí mismo recursivamente para procesar los datos de forma eficiente.
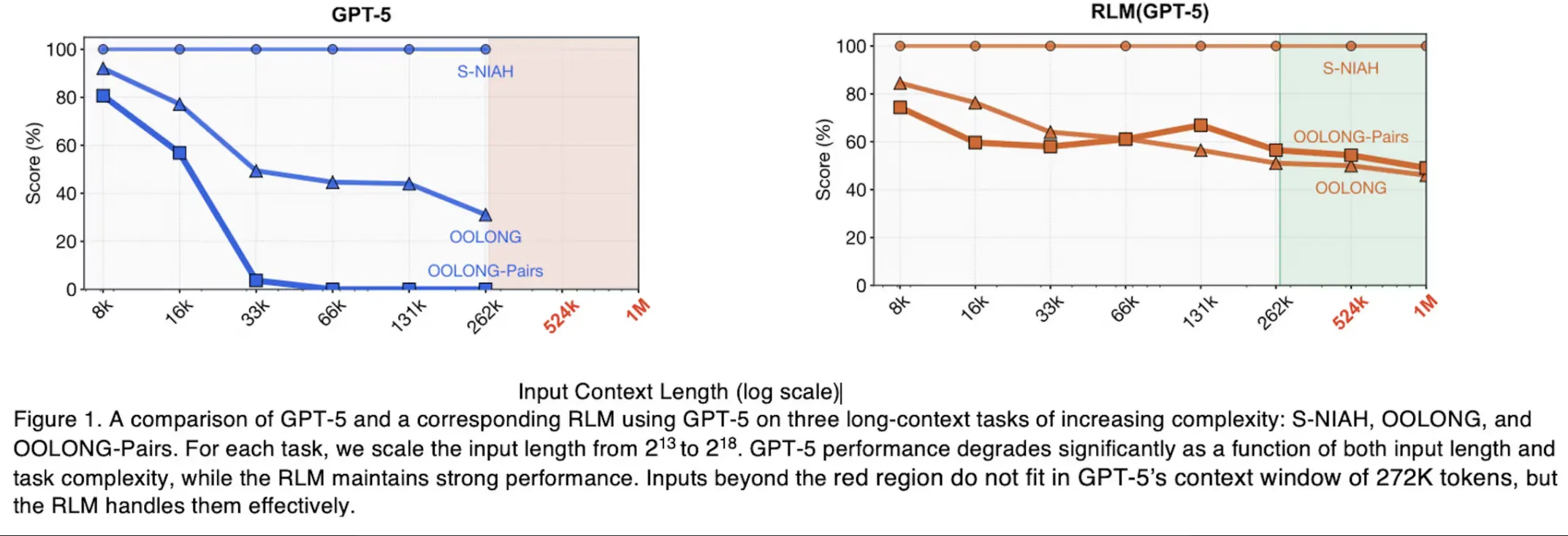
Resultados experimentales
El paper de investigación proporciona comparaciones directas entre GPT-5 estándar y GPT-5 habilitado con RLM. A medida que el tamaño del contexto escala, el RLM supera consistentemente al modelo base o se mantiene altamente estable.
Los experimentos midieron el rendimiento en varios tipos de tareas:
- S-NIAH (Single Needle In A Haystack): Encontrar una frase o número específico oculto dentro de un conjunto masivo de texto no relacionado.
- OOLONG Benchmark: Requiere que el modelo analice cada fragmento individual de un documento masivo y los agregue para formar una respuesta final.
- OOLONG-Pairs Benchmark: Fuerza al modelo a realizar razonamiento cuadrático — debe comparar cada pieza de información del documento contra todas las demás.
La idea detrás del RLM
En una configuración tradicional, cuando un usuario ingresa un prompt, un tokenizador convierte el texto en tokens. Estos tokens se alimentan directamente en la ventana de contexto del modelo Transformer para su procesamiento.
Con el RLM, este paradigma cambia por completo. La entrada del usuario no se alimenta directamente al Transformer. En su lugar, se trata como un entorno externo con el que el LLM puede interactuar recursivamente.
El mecanismo clave: REPL + Recursión
Así funciona en la práctica:
- Inicialización REPL: Dado un prompt, el RLM inicializa un entorno de programación Read-Eval-Print Loop (REPL) y asigna el prompt masivo como el valor de una variable.
- Contexto al modelo base: El RLM proporciona al modelo de lenguaje base contexto general sobre este nuevo entorno REPL.
- Generación de código: El modelo entiende la estructura y escribe código ejecutable para leer la variable, dividirla en sub-tareas manejables y procesarla mediante llamadas recursivas.
En la práctica, el RLM actúa como un wrapper alrededor del modelo de lenguaje base. Intercepta la entrada del usuario, la coloca en el entorno REPL y delega la carga de trabajo. Esta arquitectura habilita:
- Tokens de entrada ilimitados
- Tokens de salida ilimitados
- Trabajo semántico ilimitado
¿Qué significa "trabajo semántico ilimitado"?
Significa que el modelo puede mantener un razonamiento profundo, complejo y comprensivo a través de todo el conjunto de datos, sin importar cuánto crezca la información subyacente. Este enfoque abre la puerta a mayor precisión con menor coste computacional.
Observaciones clave del rendimiento
Los experimentos recientes, probando RLMs contra modelos frontera como GPT-5 de OpenAI y Qwen3-Coder de Alibaba, revelaron varias ventajas:
Escala masiva sin perder el contexto: Los RLM pueden procesar más de 10 millones de tokens y aún superar a los modelos base en tareas de contexto largo.
Arquitectura de doble mecanismo: El entorno REPL es lo que maneja la longitud de entrada masiva descargando el contexto a un espacio programable. Y la recursión de sub-llamadas es lo que da a los RLM su ventaja en tareas densas en información como OOLONG y OOLONG-Pairs.
Escalabilidad elegante: A medida que la longitud de entrada y la complejidad del problema aumentan, el rendimiento estándar de la IA cae proporcionalmente. Los RLM, sin embargo, mantienen alta precisión exactamente donde los modelos frontera más avanzados empiezan a degradarse.
Coste comparable: En promedio, el coste de inferencia de un RLM es comparable al de un modelo base estándar. Sin embargo, los costes pueden variar significativamente de una ejecución a otra, ya que el modelo ajusta dinámicamente el número de sub-llamadas según la complejidad de la tarea.
Agnóstico al modelo: La arquitectura RLM es fundamentalmente agnóstica al modelo, sirviendo como una estrategia de inferencia flexible. El modelo fine-tuneado RLM-Qwen3-8B supera al Qwen3-8B subyacente en un 28.3% en promedio y se acerca al rendimiento de GPT-5 en ciertas tareas de contexto largo.
Limitaciones actuales y lo que viene
Aunque los RLM ofrecen una mejora masiva en la escalabilidad del contexto, vienen con compromisos de ingeniería:
- Profundidad de recursión limitada: Actualmente la arquitectura está limitada a una profundidad de recursión de uno.
- Procesamiento síncrono: Las sub-llamadas se ejecutan de forma síncrona, por lo que el procesamiento puede tomar minutos.
- Costes impredecibles: La naturaleza dinámica de las sub-llamadas significa que el tiempo de ejecución y el coste pueden ser impredecibles para cualquier consulta individual.
El futuro de los RLM
Las iteraciones futuras probablemente introducirán procesamiento paralelo asíncrono para reducir la latencia, recursión jerárquica para razonamiento más profundo, y modelos entrenados nativamente desde cero para operar dentro de la arquitectura RLM. Los investigadores ya han entrenado con éxito el primer modelo nativamente recursivo (RLM-Qwen3-8B), demostrando que esto no es solo un truco temporal de scaffolding.
La ingeniería de contexto sigue siendo tu mejor arma hoy
Mientras esperamos que estas nuevas arquitecturas maduren, la ingeniería de contexto sigue siendo la estrategia más práctica y efectiva para combatir las alucinaciones y la degradación del contexto.
El enfoque de Boris Tane para usar Claude Code en producción es un ejemplo perfecto de esta disciplina aplicada. Su flujo de trabajo en tres fases demuestra principios clave:
- Investigación primero: Instruir a la IA para que estudie profundamente el código relevante antes de escribir una sola línea.
- Planificación iterativa: Crear y refinar un plan detallado con múltiples ciclos de anotación humana antes de implementar.
- Implementación controlada: Solo cuando el plan está aprobado, ejecutar con feedback continuo y verificación de tipos.
La regla de oro: nunca dejes que la IA escriba código hasta que hayas revisado y aprobado un plan escrito. Este principio no es solo buena práctica; es ingeniería de contexto pura — estás diseñando y controlando activamente el flujo de información que el modelo recibe.
Reflexiones finales
Los Modelos Recursivos de Lenguaje representan un cambio de paradigma fundamental en cómo manejamos la ingestión de prompts y el problema de la ventana de contexto. En lugar de alimentar entrada masiva en una memoria interna fija, los RLM descargan ese contexto a un entorno programable externo, habilitando longitudes teóricamente ilimitadas tanto en entradas como en salidas.
La próxima ola de modelos fundacionales probablemente dependerá de estos principios para resolver las limitaciones de memoria de forma nativa, tratando la gestión del contexto como un sistema distribuido altamente eficiente.
Pero hasta que eso llegue, recuerda: la mejor defensa contra las alucinaciones no es esperar a que el modelo sea perfecto. Es dominar la ingeniería de contexto y aplicarla en cada interacción.
Referencias y enlaces
- Recursive Language Models — Paper original de MIT (arXiv) — Alex L. Zhang, Tim Kraska, Omar Khattab
- How I Use Claude Code — Boris Tane (Cloudflare) — Flujo de trabajo práctico de ingeniería de contexto para desarrollo en producción
- Context Engineering: La Arquitectura de la IA Confiable — Nuestro artículo sobre cómo diseñar el contexto para obtener resultados confiables de los LLM
- El mito del contexto infinito: por qué el problema no son solo los tokens — Análisis profundo del límite de contexto y por qué más tokens no resuelven el problema
- GLM-5: del vibe coding a la ingeniería agentiva — Cómo los modelos modernos están evolucionando hacia arquitecturas más inteligentes