Appearance
Compactación rápida del KV Cache mediante Attention Matching: contextos largos al fin viables

Los modelos de lenguaje escalan a contextos largos, pero solo si resuelves primero un problema fundamental: la caché de clave-valor (KV cache) crece de forma explosiva. Cuando un modelo procesa un documento, almacena representaciones numéricas de cada token en memoria. Estas representaciones permiten al modelo atender a las partes relevantes del texto más adelante. Pero almacenarlo todo tiene un coste. En sistemas desplegados que manejan documentos de 10.000 tokens o más, la KV cache se convierte en el cuello de botella, no la computación del modelo en sí.
Como ya exploramos en El mito del contexto infinito, la complejidad cuadrática O(n²) de la atención y el crecimiento lineal de la KV cache son los dos grandes obstáculos para ventanas de contexto realmente largas. Ahora, un nuevo paper titulado "Fast KV Compaction via Attention Matching" propone una solución que cambia radicalmente las reglas del juego.
El problema: comprimir rápido o comprimir bien
El enfoque típico ante una KV cache desbordada es la sumarización: conservar el 10% de los tokens y descartar el resto. Los ahorros son inmediatos pero el coste está oculto. El rendimiento cae porque los resúmenes pierden matices, detalles específicos y estructura temporal. Las tareas posteriores se resienten.
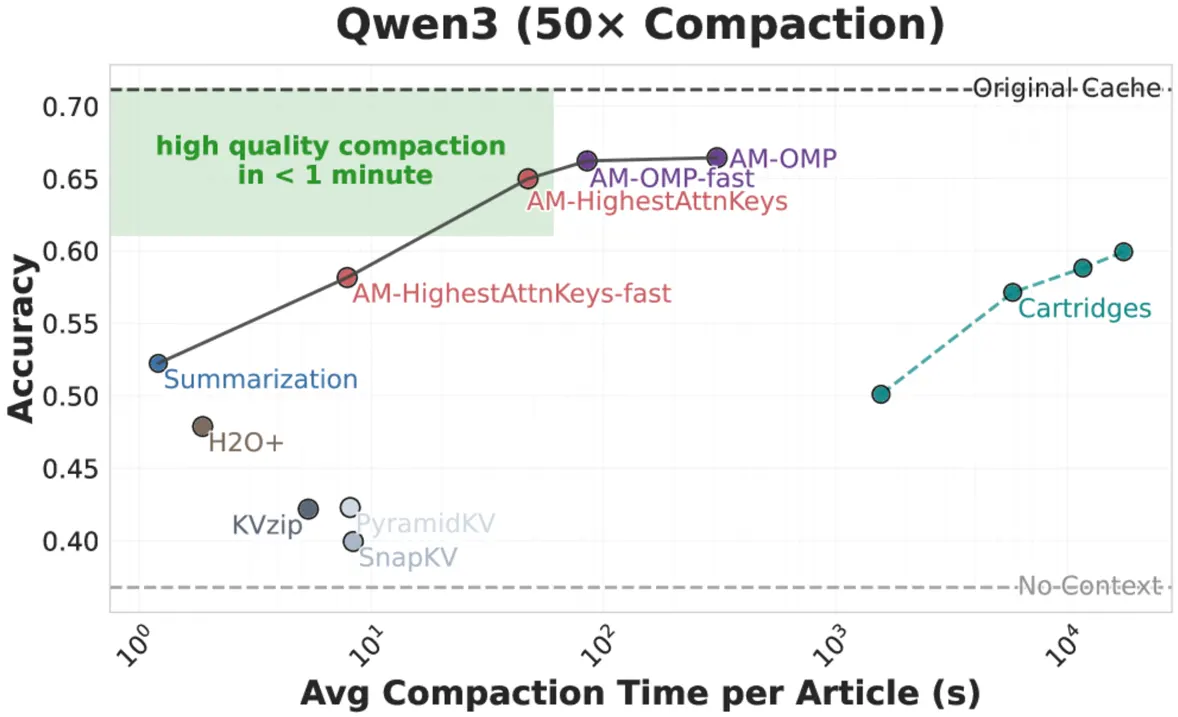
Existe otra clase de soluciones que intenta optimizar qué tokens conservar. Trabajos anteriores como Cartridges demuestran que se puede entrenar un compresor de extremo a extremo: ejecutar el modelo completo hacia adelante, medir la pérdida, retropropagar gradientes e iterar hacia una caché comprimida mejor. Esto produce resultados de alta calidad, pero tarda horas por contexto. En producción, eso es inaceptable. Cada petición de usuario trae un contexto nuevo. Necesitas compresión en segundos.
Esto crea un dilema aparentemente inevitable: la compresión rápida pierde calidad, la compresión lenta la preserva. Este paper demuestra que el dilema es falso. Existe un tercer camino.
La atención revela qué debe preservar la compresión
La idea que lo desbloquea todo: los modelos no usan todos los tokens por igual. En cada capa, cada cabeza de atención se concentra en partes específicas de la entrada a través de un mecanismo medible llamado atención. Los pesos de atención indican exactamente qué tokens toca realmente el razonamiento del modelo.
Esto replantea completamente el problema de compresión. En lugar de preguntar "¿qué es semánticamente importante?", la pregunta correcta es: "¿a qué tokens atiende realmente el modelo?" Si puedes construir una caché comprimida que haga que el modelo atienda de la misma manera, se comportará de forma casi idéntica, incluso si algunos tokens de fondo desaparecen.
Esto no es lo mismo que sumarizar. No se trata de preservar significado, sino de preservar comportamiento mecánico. Los patrones de atención del modelo son su propio plano de compresión.
El trabajo previo optimizaba esto de extremo a extremo, tratando al modelo como una caja negra y ajustando lentamente la caché comprimida hasta que las salidas de atención coincidieran. Eso requiere cientos de pasadas hacia adelante y actualizaciones de gradientes. Pero hay un camino más rápido: resolver la caché comprimida matemáticamente, directamente, sin tocar los pesos del modelo. Una vez reconoces que las salidas de atención son lo que importa, el problema se descompone en subproblemas limpios. Algunos admiten soluciones de forma cerrada, álgebra directa, sin iteración necesaria.
Este replanteamiento matemático es de donde viene la aceleración de 50x.
Descomponiendo la atención en subproblemas resolubles
La salida de atención para una sola cabeza sigue una fórmula simple: softmax(Q @ K.T) @ V. Dada una caché completa y un tamaño objetivo, el problema es encontrar un subconjunto de claves y valores que produzca salidas de atención lo más cercanas posible al original.
Este problema de emparejamiento se descompone naturalmente. Cada cabeza de atención se convierte en un subproblema independiente. Esa independencia es matemáticamente valiosa: resuelves cientos de problemas pequeños en lugar de uno enorme.
El enfoque general se divide en dos etapas:
Etapa 1: Seleccionar qué tokens conservar
Surgen varias estrategias, cada una en diferentes puntos del equilibrio velocidad-calidad:
- Selección greedy: elegir los tokens que reciben el mayor peso de atención total entre todas las consultas. Es rápida, no requiere iteración y a menudo funciona sorprendentemente bien.
- Orthogonal Matching Pursuit (OMP): un algoritmo del procesamiento de señales que selecciona tokens iterativamente para minimizar el error de reconstrucción. Más lento que greedy pero produce cachés comprimidas de mayor calidad.
- Variantes con asignación adaptativa: diferentes cantidades de tokens para diferentes cabezas, según su sensibilidad.
Etapa 2: Ajustar los valores óptimamente
Una vez decidido qué tokens conservar, se puede resolver sus valores óptimos en forma cerrada. Es un problema de mínimos cuadrados, y el álgebra lineal proporciona una solución exacta. No estás aproximando, sino resolviendo un problema más pequeño de forma más eficiente.
La sensibilidad de las cabezas expone oportunidades de compresión no uniforme
Un enfoque greedy ingenuo seleccionaría los tokens de mayor atención globalmente, aplicando la misma ratio de compresión a todas las cabezas. Pero las cabezas no son iguales.
Las pruebas lo revelan dramáticamente. Fijando todas las cabezas KV a una ratio de compresión base y variando la ratio de una sola cabeza mientras se mide el cambio en la pérdida: algunas cabezas toleran compresión de 50x con impacto mínimo, mientras que otras se degradan significativamente al comprimirlas a 10x. Esta variación es sustancial y consistente entre modelos y conjuntos de datos.
Este descubrimiento motiva la asignación adaptativa: en lugar de un presupuesto de compresión uniforme, se puede resolver la distribución óptima. Dar ratios de compresión más altas a las cabezas robustas y gastar el presupuesto de tokens en las cabezas sensibles. Similar a como un ser humano resumiría de forma diferente según la materia: comprimir lo repetitivo, preservar los detalles críticos.
Este concepto de activación selectiva recuerda al principio fundamental detrás de las arquitecturas Mixture of Experts: no todo necesita estar activo siempre. Así como MoE activa solo los expertos necesarios de un modelo masivo, Attention Matching conserva solo los tokens que cada cabeza realmente necesita.
Las decisiones de diseño importan y los resultados lo confirman
Varias decisiones dieron forma al método final:
¿Qué consultas usar para medir patrones de atención? El paper prueba ocho variantes. Los métodos basados en autoestudio (self-study), donde se muestrean las propias consultas predichas por el modelo, funcionan mejor, especialmente a ratios de compresión altas. Tiene sentido intuitivo: estás comprimiendo para patrones de atención realistas, no teóricos.
¿Cómo agregar pesos de atención al decidir qué tokens importan? Se puede sumar entre todas las cabezas, promediar, tomar el máximo por token u otras funciones. Diferentes agregaciones resaltan diferentes tokens como importantes. Pero el método es estable a través de todas ellas. Esta robustez genera confianza en que el enfoque no es frágil ni dependiente de una elección afortunada.
Validación en benchmarks reales
Todo depende de si la compactación rápida realmente funciona para tareas posteriores. El paper evalúa en QuALITY (comprensión lectora con documentos largos) y LongHealth (respuesta a preguntas médicas), dos benchmarks con contextos reales donde comprender información específica es crucial.
Los resultados confirman la intuición: se puede comprimir la KV cache al 5-10% de su tamaño original con pérdida de precisión insignificante, en segundos, usando AM-OMP o variantes greedy más simples. Compárese con Cartridges, el estado del arte anterior, que requiere cientos de segundos para alcanzar calidad similar.
Esta aceleración no es una mejora marginal. Es la diferencia entre viable e impracticable. No puedes precomputar cachés KV para cada posible consulta de usuario. En producción, comprimes al vuelo, por petición. Horas de optimización rompen tu sistema. Segundos de optimización encajan en el presupuesto de latencia.
A través de múltiples modelos (Llama 3.1-8B y Qwen3-4B), el patrón se mantiene. Los métodos rápidos alcanzan precisión similar a los métodos lentos con la misma ratio de compresión.
Cada componente contribuye: validación por ablación
Para validar que cada componente contribuye significativamente, el paper realiza experimentos de ablación (leave-one-out):
- Eliminar la selección OMP y revertir a selección greedy pura perjudica el rendimiento, especialmente a compresión alta.
- Eliminar la optimización de valores (la etapa de ajuste en forma cerrada) también degrada la calidad.
- Eliminar la asignación adaptativa (la optimización por cabeza) reduce el rendimiento.
Cada componente tiene peso. El método no está sobreingeniado; es mínimo y cada pieza es necesaria.
La pérdida de reconstrucción predice el rendimiento final
Un hallazgo clave: la pérdida de reconstrucción por cabeza (cuán bien las salidas de atención comprimidas coinciden con las originales) correlaciona con la precisión final en tareas posteriores. Esto valida el propio objetivo de optimización.
Esta correlación importa porque justifica todo el planteamiento. Estás optimizando lo correcto. Preservar las salidas de atención preserva el comportamiento posterior. No es una suposición, está empíricamente validado.
Por qué funciona donde otros métodos fallan
La aceleración proviene de dos fuentes: elegir un problema mejor estructurado y resolverlo directamente en lugar de indirectamente.
Cartridges optimiza de extremo a extremo: ejecuta el modelo completo, mide la pérdida, retropropaga por todo el grafo computacional, actualiza la caché comprimida, repite. Esta es optimización indirecta a través de una función compleja. Requiere cientos de iteraciones, cada una costosa.
Attention Matching resuelve el problema directamente. Formula el problema de emparejamiento matemáticamente y lo resuelve usando álgebra y algoritmos eficientes. Para algunos subproblemas hay solución de forma cerrada sin iteración. Para otros como OMP, la iteración es necesaria pero el problema es lo suficientemente pequeño como para completarse en milisegundos.
No estás ajustando millones de parámetros indirectamente. Estás resolviendo un problema concreto de dimensión unos pocos cientos directamente. Es la consecuencia natural de elegir un problema que las matemáticas pueden manejar eficientemente.
Cuándo funciona la compresión y cuándo no
El método destaca en tareas donde la atención del modelo es dispersa y estructurada: comprensión lectora de documentos largos, recuperación de información, respuesta a preguntas sobre contexto. Todas tienen patrones de atención comprimibles. El modelo se centra en las partes relevantes e ignora las irrelevantes.
El método es menos efectivo en tareas donde cada token atiende a casi todos los demás. Si la atención es densa, no puedes comprimir significativamente sin perder información. El paper no reclama compresión universal, solo compresión rápida y de alta calidad para cargas de trabajo prácticas con contexto largo.
Conexión con el ecosistema más amplio de optimización
Este trabajo conecta con una literatura creciente sobre inferencia eficiente para contextos largos, un tema que hemos explorado extensamente en este blog:
- Las técnicas como FlashAttention, GQA, MLA y PagedAttention que describimos en El mito del contexto infinito abordan el problema desde la arquitectura de atención. Attention Matching es complementario: comprime lo almacenado, no el cómputo.
- Los Modelos Recursivos de Lenguaje (RLM) atacan el problema del contexto largo desde otro ángulo: evitar que el modelo necesite todo el contexto de una vez mediante procesamiento recursivo.
- El enfoque de Context Engineering propone gestionar inteligentemente qué contexto entra al modelo. Attention Matching lleva esta filosofía al nivel mecánico: no solo decides qué texto enviar, sino qué representaciones internas preservar.
- Las soluciones de despliegue local como las exploradas en OpenClaw se beneficiarían enormemente de esta técnica, ya que la VRAM limitada de GPUs de consumo es precisamente donde la compresión de KV cache tiene mayor impacto.
Por qué Attention Matching cambia las reglas del juego
Durante años, la compresión de KV cache se consideró un problema aprendido: entrenar un compresor, aprender qué importa, optimizar de extremo a extremo a través del modelo. Este planteamiento lo hacía caro porque estabas ajustando algo abstracto (la caché comprimida) mediante retroalimentación indirecta (la pérdida final).
Este paper revela que es un problema estructural. La atención del modelo es visible y medible. Al comprimir a favor de la estructura de atención, en lugar de luchar contra ella, obtienes velocidad y calidad simultáneamente. La compresión se vuelve mecánica en lugar de aprendida. Las matemáticas se encargan.
La realización profunda es que los modelos no consumen información de manera uniforme. Tienen estructura. La atención es esa estructura, hecha visible. La compresión debería explotar la estructura, no combatirla.
Este principio probablemente se extiende más allá del KV caching. La memoria de activaciones y el cómputo también tienen estructura. El trabajo futuro podría plantear la misma pregunta: ¿qué está usando realmente el modelo? Una vez identificado eso, puedes comprimir a lo largo de esas líneas de manera eficiente y matemática.
Implicaciones prácticas inmediatas
Para quienes despliegan modelos de contexto largo hoy, la conclusión es directa:
- 5-10x más contexto en la misma huella de memoria.
- Sin precomputar compresión ni pérdida significativa de calidad.
- Compresión por petición en producción, dentro del presupuesto de latencia.
- Base matemática sólida: el enfoque es predecible y principista.
La KV cache ha sido durante mucho tiempo el elefante en la habitación de la inferencia de LLMs. Attention Matching no solo domestica ese elefante, sino que lo hace en el tiempo que tarda en llegar la siguiente petición del usuario.
Fuente: Fast KV Compaction via Attention Matching — Análisis basado en el resumen de AIModels.fyi.