Appearance
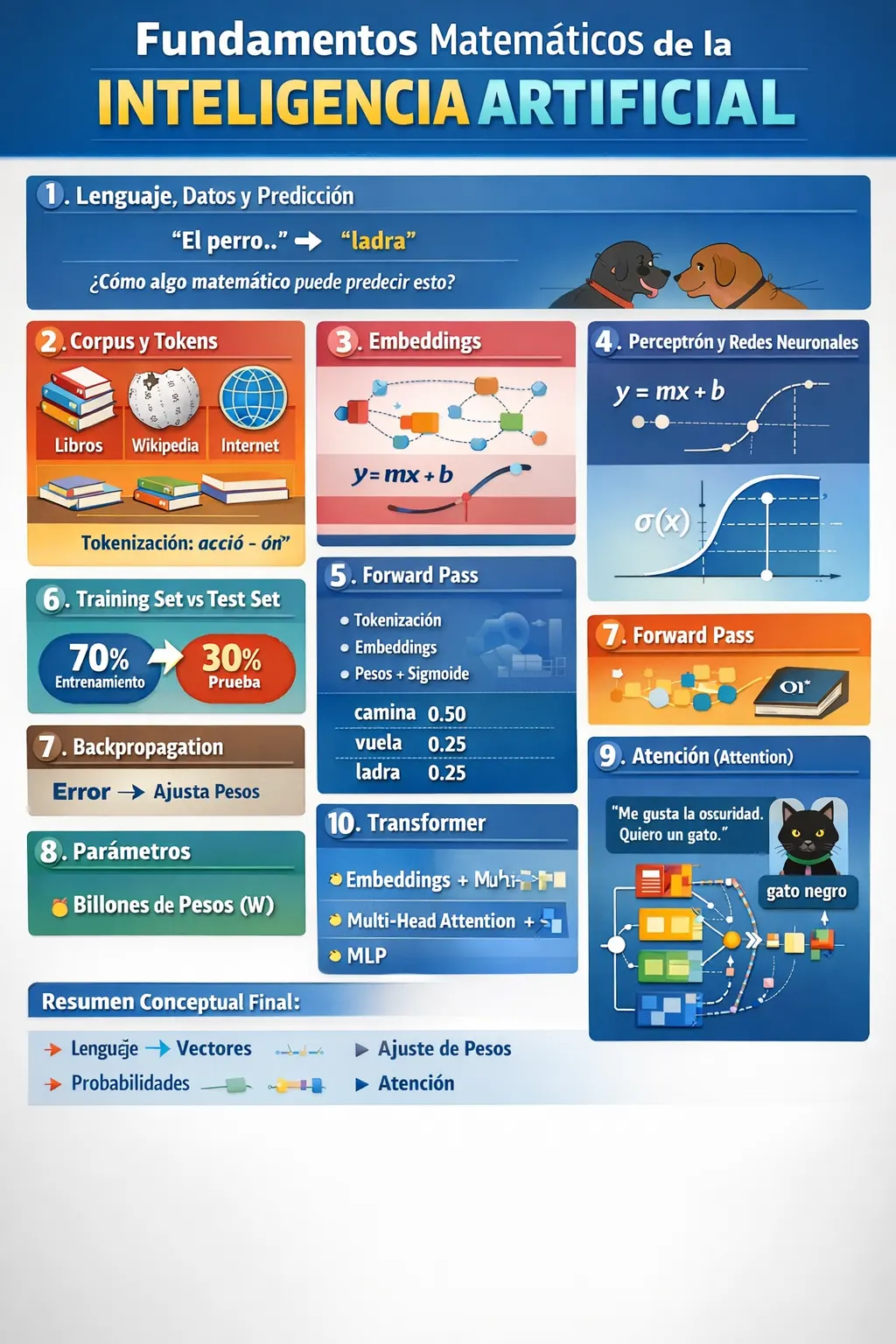
Fundamentos matemáticos de un LLM: de tokens a Transformers

¿Qué es un LLM?
Un LLM (Large Language Model) es un sistema de optimización matemática que opera sobre lenguaje representado como vectores. No piensa. No razona. Predice la siguiente palabra más probable dado un contexto, usando álgebra lineal, cálculo diferencial y estadística a escala masiva.
Existe mucha confusión sobre qué hace realmente un modelo de lenguaje por dentro. Se habla de "inteligencia", de "razonamiento", de "comprensión". Pero la realidad es más precisa y más elegante: todo se reduce a matemáticas.
Este artículo descompone, paso a paso, los fundamentos matemáticos que hacen funcionar a un LLM. Desde la tokenización hasta la arquitectura Transformer completa.
1. El punto de partida: lenguaje, datos y predicción
Un modelo de lenguaje recibe un prompt:
"El perro…"
Y debe predecir la palabra más probable siguiente:
"ladra"
Originalmente, los modelos eran autocompletadores estadísticos puros. La pregunta central siempre fue:
¿Cómo algo matemático puede predecir que "el perro" → "ladra"?
La respuesta involucra varias capas de abstracción matemática que se apilan de forma elegante.
2. Corpus, diccionario y tokens
El corpus
El corpus es el conjunto de datos textuales con los que se entrena el modelo. Incluye:
- Libros
- Wikipedia
- Internet (páginas web filtradas)
- Código fuente
- Documentos académicos
Matiz importante
El corpus no contiene "todas las palabras posibles". Contiene las observadas en el dataset de entrenamiento. Lo que no aparece en el corpus, el modelo no lo conoce directamente.
Tokenización
El modelo no trabaja con letras ni palabras directamente. Convierte texto en tokens: unidades subléxicas optimizadas estadísticamente.
| Texto | Tokens posibles |
|---|---|
"acción" | 1 token |
"satisfacción" | satis + facción |
"extraordinario" | extra + ordinario |
Esto se logra con algoritmos como BPE (Byte Pair Encoding), que busca:
- Minimizar el número total de tokens
- Maximizar la eficiencia de representación
Meta exploró una alternativa radical a la tokenización con el Byte Latent Transformer (BLT), que elimina los tokens y trabaja directamente con bytes.
Texto original: "El perro ladra fuerte"
Tokenización BPE:
"El" → Token 152
" perro" → Token 8934
" ladra" → Token 23401
" fuerte"→ Token 5672
Vector de entrada: [152, 8934, 23401, 5672]Cada token se convierte en un número. Y con números, ya podemos hacer matemáticas.
3. Embeddings: el lenguaje como espacio vectorial
Cada token se convierte en un vector en un espacio de N dimensiones. Esto es la base de todo.
Ejemplo conceptual
| Palabra | Dim. Género | Dim. Progenitor | Dim. Edad |
|---|---|---|---|
| papá | +hombre | +progenitor | +adulto |
| mamá | +mujer | +progenitor | +adulto |
| hijo | +hombre | −progenitor | −adulto |
Esto permite operaciones algebraicas sobre el significado:
papá − género_masculino ≈ progenitor
progenitor + género_femenino ≈ mamá
rey − hombre + mujer ≈ reinaEs álgebra vectorial aplicada al lenguaje.
Matiz importante
No existe una dimensión explícita llamada "género" o "progenitor". Estas propiedades emergen estadísticamente del entrenamiento. El modelo descubre estas relaciones por sí mismo a partir de los patrones del corpus.
Conceptos clave
| Concepto | Representación |
|---|---|
| Cada palabra | Una coordenada en el espacio |
| Cada dimensión | Una característica semántica emergente |
| Operaciones | Sumas y restas vectoriales |
| Similitud | Distancia coseno entre vectores |
Espacio de Embeddings (2D simplificado)
Progenitor
↑
mamá ●─────────● papá
│ │
│ │
hija ●─────────● hijo
│
└──────────────→ GéneroEn la realidad, los embeddings modernos tienen 768 a 12.288 dimensiones. Cada token es un punto en ese hiperespacio.
4. Perceptrón y redes neuronales
¿Qué es un perceptrón?
Es la unidad fundamental de computación neuronal. Un modelo matemático que:
- Recibe entradas (x₁, x₂, ..., xₙ)
- Las multiplica por pesos (w₁, w₂, ..., wₙ)
- Suma todo y añade un sesgo (b)
- Aplica una función de activación
- Produce una salida
Entradas Pesos Suma Activación Salida
─────────────────────────────────────────────────────────────────
x₁ ──── w₁ ──┐
├──→ Σ(wᵢxᵢ + b) ──→ σ(z) ──→ ŷ
x₂ ──── w₂ ──┤
│
x₃ ──── w₃ ──┘Fórmula básica:
z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b
ŷ = σ(z)O en forma matricial: ŷ = σ(Wx + b)
Pesos (W)
| Propiedad | Descripción |
|---|---|
| Tipo | Valores numéricos (float) |
| Inicialización | Aleatoria |
| Ajuste | Durante el entrenamiento (backpropagation) |
| Función | Determinan la importancia de cada entrada |
Función de activación: la sigmoide
La función sigmoide transforma cualquier número real en un valor entre 0 y 1:
σ(x) = 1 / (1 + e⁻ˣ) Salida
1.0 │ ●●●●●●●●●●
│ ●●●●
│ ●●●
0.5 │─ ─ ─ ─ ─ ─ ─ ─●●─ ─ ─ ─ ─ ─ ─ ─ ─
│ ●●●
│ ●●●●
0.0 │●●●●●●●●●●
└─────────────────────────────────────
-6 -4 -2 0 2 4 6
Entrada (x)Propiedades críticas:
- Rango: (0, 1)
- Es suave (continua)
- Es derivable en todo punto
- La derivabilidad permite aplicar cálculo diferencial → backpropagation
Nota
En modelos modernos se usan otras funciones como ReLU, GELU o SiLU, pero la sigmoide ilustra el principio fundamental.
5. Forward Pass: de texto a probabilidades
El forward pass es el proceso completo de convertir texto en predicciones:
Texto → Tokens → Embeddings → Capas neurales → Probabilidades
Paso 1: "El perro" → [152, 8934]
Paso 2: [152, 8934] → [[0.2, -0.5, 0.8, ...], [0.7, 0.1, -0.3, ...]]
Paso 3: Multiplicación por matrices de pesos W
Paso 4: Aplicación de funciones de activación
Paso 5: Capa final → distribución de probabilidad sobre todo el vocabularioEjemplo de salida
Predicción siguiente palabra para "El perro..."
camina ████████████████████████████ 0.35
ladra ██████████████████████████ 0.30
corre ████████████████ 0.18
duerme █████████████ 0.12
vuela ███ 0.05El modelo produce una distribución de probabilidad sobre todas las palabras posibles del vocabulario (50.000+ tokens). La siguiente palabra se selecciona mediante muestreo de esta distribución.
6. Training Set vs Test Set
Para entrenar y evaluar, el dataset se divide:
Dataset completo
╔══════════════════════════════════════════════╗
║ ENTRENAMIENTO (70-80%) │ TEST (20-30%) ║
║ El modelo aprende de │ El modelo se ║
║ estos datos │ evalúa aquí ║
╚══════════════════════════════════════════════╝| Conjunto | Propósito | Acceso del modelo |
|---|---|---|
| Training set | Ajustar pesos | Ve estos datos durante el entrenamiento |
| Test set | Evaluar rendimiento real | Nunca los ve durante el entrenamiento |
| Validation set | Ajustar hiperparámetros | Evaluación intermedia |
¿Por qué dividir?
Para evitar el overfitting: que el modelo memorice los datos en lugar de aprender patrones generalizables.
Si el modelo predice → "camina" (probabilidad 0.50)
Pero el corpus dice → "ladra" (es la respuesta correcta)
Error = diferencia entre predicción y realidad
→ El modelo debe ajustarseEsa señal de error es exactamente lo que alimenta el siguiente paso: backpropagation.
7. Backpropagation: aprender del error
Backpropagation (retropropagación) es el algoritmo que permite al modelo aprender. Funciona en tres pasos:
1. FORWARD PASS 2. CALCULAR ERROR 3. AJUSTAR PESOS
────────────────→ ──────────────────→ ←────────────────
Entrada → Salida Salida vs Esperado Pesos actualizados
(función de pérdida) (gradiente descendente)La clave matemática: derivadas
La derivada de la función de pérdida respecto a cada peso indica:
- Dirección: ¿subo o bajo el peso?
- Magnitud: ¿cuánto lo ajusto?
Función de pérdida L(w)
L │
│ ╲
│ ╲ ← Pendiente (derivada) indica
│ ╲ la dirección del ajuste
│ ╲
│ ╲
│ ◉ ← Queremos llegar aquí (mínimo)
│ ╱
│ ╱
└──────────────→ w (peso)Regla de la cadena
En redes con múltiples capas, el error se propaga hacia atrás usando la regla de la cadena del cálculo:
∂L/∂w₁ = ∂L/∂ŷ × ∂ŷ/∂z × ∂z/∂w₁Cada capa contribuye a su porción del gradiente. El proceso se repite por épocas (pasadas completas sobre el dataset) hasta que el error converge.
| Concepto | Función |
|---|---|
| Función de pérdida | Mide qué tan mal predice el modelo |
| Gradiente | Vector de derivadas parciales |
| Learning rate | Controla el tamaño de cada ajuste |
| Época | Una pasada completa sobre el dataset |
8. Parámetros: la escala de los LLM
Un parámetro = un peso ajustable en el modelo.
| Modelo | Parámetros | Escala |
|---|---|---|
| GPT-2 (2019) | 1.500 millones | 1.5B |
| GPT-3 (2020) | 175.000 millones | 175B |
| GPT-4 (2023) | ~1.8 billones (estimado, MoE) | ~1.8T |
| Llama 3.1 (2024) | 405.000 millones | 405B |
| DeepSeek-V3 (2025) | 671.000 millones (MoE) | 671B |
Cada parámetro es un número decimal que se ajusta durante el entrenamiento. Más parámetros no significa necesariamente mejor modelo, como explora el artículo sobre por qué más grande ya no escala y cómo las arquitecturas MoE (Mixture of Experts) activan solo una fracción de los parámetros por cada token.
Matiz importante
Cuando se habla de "un modelo de 70B parámetros", eso significa 70.000 millones de pesos individuales que fueron ajustados mediante backpropagation durante semanas o meses de entrenamiento en miles de GPUs.
9. Atención (Attention): el mecanismo que cambió todo
El problema
Sin atención, el modelo trata todas las palabras del contexto con la misma importancia. Pero el lenguaje no funciona así.
Ejemplo
"Me gusta la oscuridad. Quiero un gato."
| Sin atención | Con atención |
|---|---|
| gato → genérico | gato → negro (influido por "oscuridad") |
La atención permite al modelo ponderar dinámicamente qué partes del contexto son relevantes para cada predicción.
Query, Key, Value (Q, K, V)
Cada token genera tres vectores:
| Vector | Analogía | Función |
|---|---|---|
| Query (Q) | "¿Qué estoy buscando?" | Lo que el token actual necesita saber |
| Key (K) | "¿Qué tengo para ofrecer?" | Lo que cada token puede aportar |
| Value (V) | "¿Qué información transfiero?" | El contenido real que se transmite |
Fórmula de atención
Attention(Q, K, V) = softmax(Q × Kᵀ / √dₖ) × VDonde:
- Q × Kᵀ: Producto punto entre queries y keys (¿cuánto coinciden?)
- √dₖ: Factor de escala (evita que los valores crezcan demasiado)
- softmax: Convierte los scores en probabilidades (suman 1)
- × V: Pondera los valores según la relevancia calculada
Mecanismo de Atención (simplificado)
Token: "El" "gato" "negro" "duerme"
│ │ │ │
▼ ▼ ▼ ▼
Query: Q₁ Q₂ Q₃ Q₄
Key: K₁ K₂ K₃ K₄
Value: V₁ V₂ V₃ V₄
Para predecir después de "duerme":
Score("duerme", "El") = Q₄·K₁ = 0.1 (poco relevante)
Score("duerme", "gato") = Q₄·K₂ = 0.6 (muy relevante)
Score("duerme", "negro") = Q₄·K₃ = 0.2 (algo relevante)
Score("duerme", "duerme")= Q₄·K₄ = 0.1
Softmax → [0.08, 0.52, 0.22, 0.18]
Salida = 0.08·V₁ + 0.52·V₂ + 0.22·V₃ + 0.18·V₄
= embedding contextualizado de "duerme"El resultado es un nuevo embedding contextualizado: la representación del token ya no depende solo de sí mismo, sino de todo el contexto ponderado.
Como se analiza en el mito del contexto infinito, este mecanismo tiene un coste O(n²) que limita la ventana práctica de atención, y la compactación del KV Cache es una de las técnicas para mitigar este problema.
10. Transformer: la arquitectura completa
El Transformer es la arquitectura que unifica todo lo anterior. Fue introducido en el paper "Attention Is All You Need" (Vaswani et al., 2017) y es la base de todos los LLM modernos.
Estructura de un bloque Transformer
┌─────────────────────────────────────┐
│ BLOQUE TRANSFORMER │
│ │
│ Input Embeddings + Pos. Encoding │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Multi-Head Attention│ │
│ │ (varias cabezas Q,K,V │
│ │ en paralelo) │ │
│ └─────────┬───────────┘ │
│ │ + Residual │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Layer Norm │ │
│ └─────────┬───────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ MLP (Feed Forward) │ │
│ │ Perceptrón multicapa│ │
│ └─────────┬───────────┘ │
│ │ + Residual │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Layer Norm │ │
│ └─────────┬───────────┘ │
│ │ │
└───────────┼─────────────────────────┘
│
▼ (se repite N veces)Multi-Head Attention
En lugar de una sola atención, el Transformer usa múltiples cabezas en paralelo:
| Cabeza | Puede aprender |
|---|---|
| Cabeza 1 | Relaciones sintácticas (sujeto-verbo) |
| Cabeza 2 | Relaciones semánticas (significado) |
| Cabeza 3 | Relaciones posicionales (cercanía) |
| Cabeza N | Otros patrones lingüísticos |
Cada cabeza opera de forma independiente y luego se concatenan los resultados.
MLP (Feed Forward)
Después de la atención, cada token pasa por un perceptrón multicapa:
FFN(x) = GELU(xW₁ + b₁)W₂ + b₂El MLP actúa como una "memoria factual" que almacena conocimiento aprendido del corpus.
Un LLM completo
Un LLM es la repetición de este bloque N veces:
| Modelo | Capas (bloques) | Cabezas de atención | Dim. embedding |
|---|---|---|---|
| GPT-2 | 48 | 25 | 1.600 |
| Llama 3 (70B) | 80 | 64 | 8.192 |
| GPT-4 (estimado) | 120+ | 96+ | 12.288+ |
Un LLM es:
Tokens → Embeddings → [Atención + MLP] × N capas → Probabilidades
│
Cada capa refina
la representación
del contextoResumen: la cadena completa
╔═══════════════════════════════════════════════════════════╗
║ PIPELINE DE UN LLM ║
╠═══════════════════════════════════════════════════════════╣
║ ║
║ 1. TEXTO "El perro ladra" ║
║ │ ║
║ ▼ ║
║ 2. TOKENS [152, 8934, 23401] ║
║ │ ║
║ ▼ ║
║ 3. EMBEDDINGS [[0.2, -0.5, ...], [0.7, 0.1, ...]] ║
║ │ Vectores en espacio n-dimensional ║
║ ▼ ║
║ 4. ATENCIÓN Ponderar contexto relevante (Q, K, V) ║
║ │ ║
║ ▼ ║
║ 5. MLP Transformación no lineal ║
║ │ ║
║ ▼ (repetir 4-5 por N capas) ║
║ ║
║ 6. SOFTMAX Distribución de probabilidad ║
║ │ ║
║ ▼ ║
║ 7. PREDICCIÓN "fuerte" (p=0.35) ║
║ ║
║ ENTRENAMIENTO: ║
║ 8. ERROR Comparar predicción vs corpus ║
║ │ ║
║ ▼ ║
║ 9. BACKPROP Ajustar pesos con gradientes ║
║ │ ║
║ ▼ (repetir millones de veces) ║
║ ║
║ 10. MODELO Miles de millones de pesos optimizados ║
║ ENTRENADO ║
║ ║
╚═══════════════════════════════════════════════════════════╝La idea central
Un LLM es optimización matemática sobre lenguaje representado como vectores.
No hay magia. No hay comprensión. No hay conciencia. Hay:
| Componente | Matemática |
|---|---|
| Tokenización | Compresión estadística (BPE) |
| Embeddings | Álgebra lineal (vectores, matrices) |
| Perceptrón | Función lineal + activación no lineal |
| Forward pass | Composición de funciones |
| Backpropagation | Cálculo diferencial (regla de la cadena) |
| Atención | Producto punto + softmax |
| Transformer | Todo lo anterior, apilado N veces |
El resultado es un sistema que, dado suficiente texto y suficiente computación, aprende a predecir la siguiente palabra con una precisión asombrosa. Y de esa simple tarea de predicción emerge lo que percibimos como "inteligencia".
La pregunta ya no es si puede predecir. Es qué emerge de la predicción a escala.
Para profundizar en cómo estos fundamentos se aplican en la práctica, consulta los artículos sobre Context Engineering y los modelos recursivos de lenguaje (RLM), que exploran cómo se están superando las limitaciones actuales.
Referencias
- Vaswani, A. et al. (2017). Attention Is All You Need. arXiv.
- Mikolov, T. et al. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv (Word2Vec).
- Sennrich, R. et al. (2016). Neural Machine Translation of Rare Words with Subword Units. arXiv (BPE).
- Rumelhart, D. et al. (1986). Learning representations by back-propagating errors. Nature.